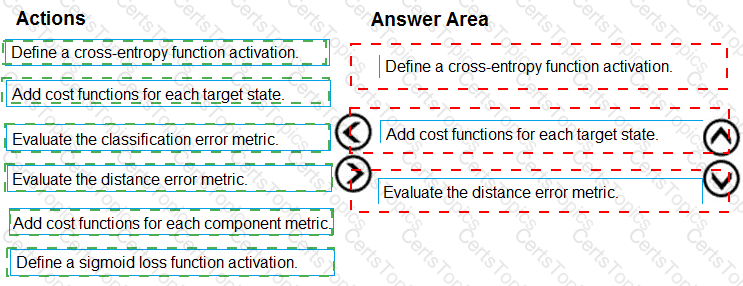
You need to define an evaluation strategy for the crowd sentiment models.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

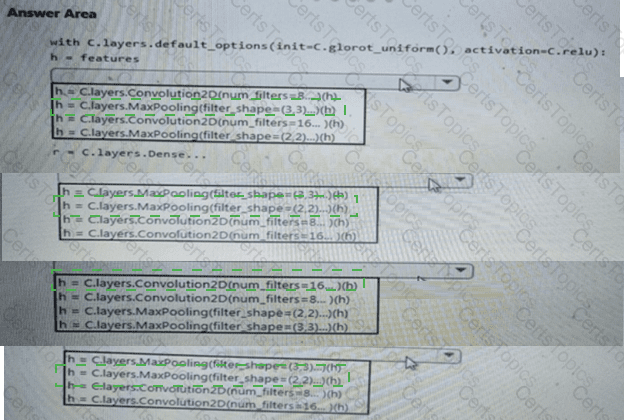
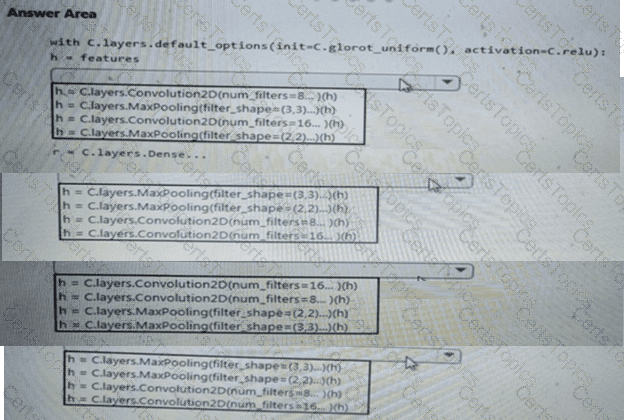
You need to build a feature extraction strategy for the local models.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You plan to implement an Azure Machine Learning solution. You have the following requirements:
• Run a Jupyter notebook to interactively tram a machine learning model.
• Deploy assets and workflows for machine learning proof of concept by using scripting rather than custom programming.
You need to select a development technique for each requirement
Which development technique should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are creating a new experiment in Azure Machine Learning Studio.
One class has a much smaller number of observations than tin- other classes in the training set.
You need to select an appropriate data sampling strategy to compensate for the class imbalance.
Solution: You use the Principal Components Analysis (PCA) sampling mode.
Does the solution meet the goal?
Copyright © 2021-2026 CertsTopics. All Rights Reserved