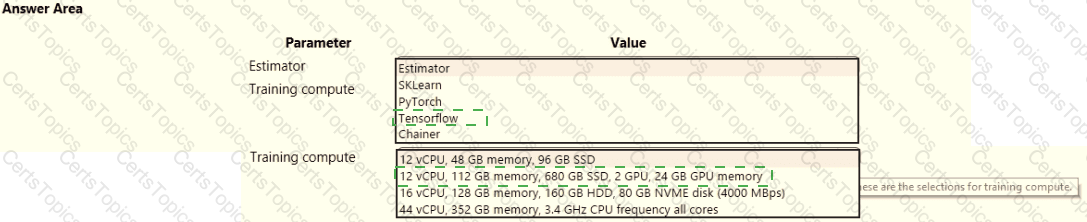
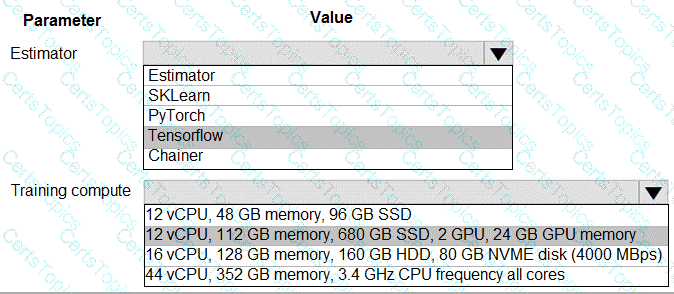
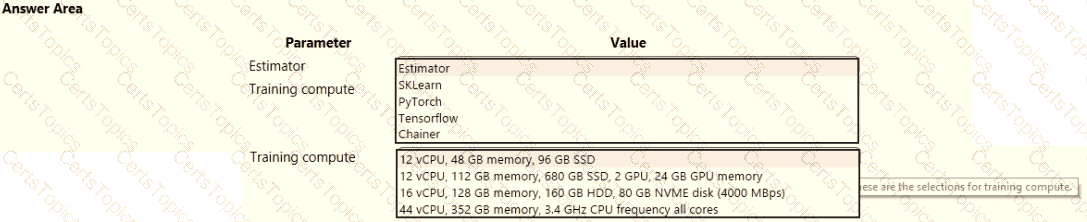
space and set up a development environment. You plan to train a deep neural network (DNN) by using the Tensorflow framework and by using estimators to submit training scripts.
You must optimize computation speed for training runs.
You need to choose the appropriate estimator to use as well as the appropriate training compute target configuration.
Which values should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You have an Azure Machine Learning (ML) model deployed to an online endpoint.
You need to review container logs from the endpoint by using Azure Ml Python SDK v2. The logs must include the console log from the inference server with print/log statements from the models scoring script.
What should you do first?
You build a data pipeline in an Azure Machine Learning workspace by using the Azure Machine Learning SDK for Python.
You need to run a Python script as a pipeline step.
Which two classes could you use? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
You are with a time series dataset in Azure Machine Learning Studio.
You need to split your dataset into training and testing subsets by using the Split Data module.
Which splitting mode should you use?
Copyright © 2021-2026 CertsTopics. All Rights Reserved