Your team has deployed an application to Production with an underperforming view. Unexpectedly, the production data is ten times that of what was tested, and you must remediate the issue. What is the best option you can take to mitigate their performance concerns?
Bypass Appian’s query rule by calling the database directly with a SQL statement.
Create a table which is loaded every hour with the latest data.
Create a materialized view or table.
Introduce a data management policy to reduce the volume of data.
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, addressing performance issues in production requires balancing Appian’s best practices, scalability, and maintainability. The scenario involves an underperforming view due to a significant increase in data volume (ten times the tested amount), necessitating a solution that optimizes performance while adhering to Appian’s architecture. Let’s evaluate each option:
A. Bypass Appian’s query rule by calling the database directly with a SQL statement:This approach involves circumventing Appian’s query rules (e.g., a!queryEntity) and directly executing SQL against the database. While this might offer a quick performance boost by avoiding Appian’s abstraction layer, it violates Appian’s core design principles. Appian Lead Developer documentation explicitly discourages direct database calls, as they bypass security (e.g., Appian’s row-level security), auditing, and portability features. This introduces maintenance risks, dependencies on database-specific logic, and potential production instability—making it an unsustainable and non-recommended solution.
B. Create a table which is loaded every hour with the latest data:This suggests implementing a staging table updated hourly (e.g., via an Appian process model or ETL process). While this could reduce query load by pre-aggregating data, it introduces latency (data is only fresh hourly), which may not meet real-time requirements typical in Appian applications (e.g., a customer-facing view). Additionally, maintaining an hourly refresh process adds complexity and overhead (e.g., scheduling, monitoring). Appian’s documentation favors more efficient, real-time solutions over periodic refreshes unless explicitly required, making this less optimal for immediate performance remediation.
C. Create a materialized view or table:This is the best choice. A materialized view (or table, depending on the database) pre-computes and stores query results, significantly improving retrieval performance for large datasets. In Appian, you can integrate a materialized view with a Data Store Entity, allowing a!queryEntity to fetch data efficiently without changing application logic. Appian Lead Developer training emphasizes leveraging database optimizations like materialized views to handle large data volumes, as they reduce query execution time while keeping data consistent with the source (via periodic or triggered refreshes, depending on the database). This aligns with Appian’s performance optimization guidelines and addresses the tenfold data increase effectively.
D. Introduce a data management policy to reduce the volume of data:This involves archiving or purging data to shrink the dataset (e.g., moving old records to an archive table). While a long-term data management policy is a good practice (and supported by Appian’s Data Fabric principles), it doesn’t immediately remediate the performance issue. Reducing data volume requires business approval, policy design, and implementation—delaying resolution. Appian documentation recommends combining such strategies with technical fixes (like C), but as a standalone solution, it’s insufficient for urgent production concerns.
Conclusion: Creating a materialized view or table (C) is the best option. It directly mitigates performance by optimizing data retrieval, integrates seamlessly with Appian’s Data Store, and scales for large datasets—all while adhering to Appian’s recommended practices. The view can be refreshed as needed (e.g., via database triggers or schedules), balancing performance and data freshness. This approach requires collaboration with a DBA to implement but ensures a robust, Appian-supported solution.
As part of your implementation workflow, users need to retrieve data stored in a third-party Oracle database on an interface. You need to design a way to query this information.
How should you set up this connection and query the data?
Configure a Query Database node within the process model. Then, type in the connection information, as well as a SQL query to execute and return the data in process variables.
Configure a timed utility process that queries data from the third-party database daily, and stores it in the Appian business database. Then use a!queryEntity using the Appian data source to retrieve the data.
Configure an expression-backed record type, calling an API to retrieve the data from the third-party database. Then, use a!queryRecordType to retrieve the data.
In the Administration Console, configure the third-party database as a “New Data Source.” Then, use a!queryEntity to retrieve the data.
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, designing a solution to query data from a third-party Oracle database for display on an interface requires secure, efficient, and maintainable integration. The scenario focuses on real-time retrieval for users, so the design must leverage Appian’s data connectivity features. Let’s evaluate each option:
A. Configure a Query Database node within the process model. Then, type in the connection information, as well as a SQL query to execute and return the data in process variables:The Query Database node (part of the Smart Services) allows direct SQL execution against a database, but it requires manual connection details (e.g., JDBC URL, credentials), which isn’t scalable or secure for Production. Appian’s documentation discourages using Query Database for ongoing integrations due to maintenance overhead, security risks (e.g., hardcoding credentials), and lack of governance. This is better for one-off tasks, not real-time interface queries, making it unsuitable.
B. Configure a timed utility process that queries data from the third-party database daily, and stores it in the Appian business database. Then use a!queryEntity using the Appian data source to retrieve the data:This approach syncs data daily into Appian’s business database (e.g., via a timer event and Query Database node), then queries it with a!queryEntity. While it works for stale data, it introduces latency (up to 24 hours) for users, which doesn’t meet real-time needs on an interface. Appian’s best practices recommend direct data source connections for up-to-date data, not periodic caching, unless latency is acceptable—making this inefficient here.
C. Configure an expression-backed record type, calling an API to retrieve the data from the third-party database. Then, use a!queryRecordType to retrieve the data:Expression-backed record types use expressions (e.g., a!httpQuery()) to fetch data, but they’re designed for external APIs, not direct database queries. The scenario specifies an Oracle database, not an API, so this requires building a custom REST service on the Oracle side, adding complexity and latency. Appian’s documentation favors Data Sources for database queries over API calls when direct access is available, making this less optimal and over-engineered.
D. In the Administration Console, configure the third-party database as a “New Data Source.” Then, use a!queryEntity to retrieve the data:This is the best choice. In the Appian Administration Console, you can configure a JDBC Data Source for the Oracle database, providing connection details (e.g., URL, driver, credentials). This creates a secure, managed connection for querying via a!queryEntity, which is Appian’s standard function for Data Store Entities. Users can then retrieve data on interfaces using expression-backed records or queries, ensuring real-time access with minimal latency. Appian’s documentation recommends Data Sources for database integrations, offering scalability, security, and governance—perfect for this requirement.
Conclusion: Configuring the third-party database as a New Data Source and using a!queryEntity (D) is the recommended approach. It provides direct, real-time access to Oracle data for interface display, leveraging Appian’s native data connectivity features and aligning with Lead Developer best practices for third-party database integration.
You are required to configure a connection so that Jira can inform Appian when specific tickets change (using a webhook). Which three required steps will allow you to connect both systems?
Create a Web API object and set up the correct security.
Configure the connection in Jira specifying the URL and credentials.
Create a new API Key and associate a service account.
Give the service account system administrator privileges.
Create an integration object from Appian to Jira to periodically check the ticket status.
Comprehensive and Detailed In-Depth Explanation:
Configuring a webhook connection from Jira to Appian requires setting up a mechanism for Jira to push ticket change notifications to Appian in real-time. This involves creating an endpoint in Appian to receive the webhook and configuring Jira to send the data. Appian’s Integration Best Practices and Web API documentation provide the framework for this process.
Option A (Create a Web API object and set up the correct security):This is a required step. In Appian, a Web API object serves as the endpoint to receive incoming webhook requests from Jira. You must define the API structure (e.g., HTTP method, input parameters) and configure security (e.g., basic authentication, API key, or OAuth) to validate incoming requests. Appian recommends using a service account with appropriate permissions to ensure secure access, aligning with the need for a controlled webhook receiver.
Option B (Configure the connection in Jira specifying the URL and credentials):This is essential. In Jira, you need to set up a webhook by providing the Appian Web API’s URL (e.g., <appian-site>/suite/webapi/
Option C (Create a new API Key and associate a service account):This is necessary for secure authentication. Appian recommends using an API key tied to a service account for webhook integrations. The service account should have permissions to process the incoming data (e.g., write to a process or data store) but not excessive privileges. This step complements the Web API security setup and Jira configuration.
Option D (Give the service account system administrator privileges):This is unnecessary and insecure. System administrator privileges grant broad access, which is overkill for a webhook integration. Appian’s security best practices advocate for least-privilege principles, limiting the service account to the specific objects or actions needed (e.g., executing the Web API).
Option E (Create an integration object from Appian to Jira to periodically check the ticket status):This is incorrect for a webhook scenario. Webhooks are push-based, where Jira notifies Appian of changes. Creating an integration object for periodic polling (pull-based) is a different approach and not required for the stated requirement of Jira informing Appian via webhook.
These three steps (A, B, C) establish a secure, functional webhook connection without introducing unnecessary complexity or security risks.
You add an index on the searched field of a MySQL table with many rows (>100k). The field would benefit greatly from the index in which three scenarios?
The field contains a textual short business code.
The field contains long unstructured text such as a hash.
The field contains many datetimes, covering a large range.
The field contains big integers, above and below 0.
The field contains a structured JSON.
Comprehensive and Detailed In-Depth Explanation:
Adding an index to a searched field in a MySQL table with over 100,000 rows improves query performance by reducing the number of rows scanned during searches, joins, or filters. The benefit of an index depends on the field’s data type, cardinality (uniqueness), and query patterns. MySQL indexing best practices, as aligned with Appian’s Database Optimization Guidelines, highlight scenarios where indices are most effective.
Option A (The field contains a textual short business code):This benefits greatly from an index. A short business code (e.g., a 5-10 character identifier like "CUST123") typically has high cardinality (many unique values) and is often used in WHERE clauses or joins. An index on this field speeds up exact-match queries (e.g., WHERE business_code = 'CUST123'), which are common in Appian applications for lookups or filtering.
Option C (The field contains many datetimes, covering a large range):This is highly beneficial. Datetime fields with a wide range (e.g., transaction timestamps over years) are frequently queried with range conditions (e.g., WHERE datetime BETWEEN '2024-01-01' AND '2025-01-01') or sorting (e.g., ORDER BY datetime). An index on this field optimizes these operations, especially in large tables, aligning with Appian’s recommendation to index time-based fields for performance.
Option D (The field contains big integers, above and below 0):This benefits significantly. Big integers (e.g., IDs or quantities) with a broad range and high cardinality are ideal for indexing. Queries like WHERE id > 1000 or WHERE quantity < 0 leverage the index for efficient range scans or equality checks, a common pattern in Appian data store queries.
Option B (The field contains long unstructured text such as a hash):This benefits less. Long unstructured text (e.g., a 128-character SHA hash) has high cardinality but is less efficient for indexing due to its size. MySQL indices on large text fields can slow down writes and consume significant storage, and full-text searches are better handled with specialized indices (e.g., FULLTEXT), not standard B-tree indices. Appian advises caution with indexing large text fields unless necessary.
Option E (The field contains a structured JSON):This is minimally beneficial with a standard index. MySQL supports JSON fields, but a regular index on the entire JSON column is inefficient for large datasets (>100k rows) due to its variable structure. Generated columns or specialized JSON indices (e.g., using JSON_EXTRACT) are required for targeted queries (e.g., WHERE JSON_EXTRACT(json_col, '$.key') = 'value'), but this requires additional setup beyond a simple index, reducing its immediate benefit.
For a table with over 100,000 rows, indices are most effective on fields with high selectivity and frequent query usage (e.g., short codes, datetimes, integers), making A, C, and D the optimal scenarios.
A customer wants to integrate a CSV file once a day into their Appian application, sent every night at 1:00 AM. The file contains hundreds of thousands of items to be used daily by users as soon as their workday starts at 8:00 AM. Considering the high volume of data to manipulate and the nature of the operation, what is the best technical option to process the requirement?
Use an Appian Process Model, initiated after every integration, to loop on each item and update it to the business requirements.
Build a complex and optimized view (relevant indices, efficient joins, etc.), and use it every time a user needs to use the data.
Create a set of stored procedures to handle the volume and the complexity of the expectations, and call it after each integration.
Process what can be completed easily in a process model after each integration, and complete the most complex tasks using a set of stored procedures.
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, handling a daily CSV integration with hundreds of thousands of items requires a solution that balances performance, scalability, and Appian’s architectural strengths. The timing (1:00 AM integration, 8:00 AM availability) and data volume necessitate efficient processing and minimal runtime overhead. Let’s evaluate each option based on Appian’s official documentation and best practices:
A. Use an Appian Process Model, initiated after every integration, to loop on each item and update it to the business requirements:This approach involves parsing the CSV in a process model and using a looping mechanism (e.g., a subprocess or script task with fn!forEach) to process each item. While Appian process models are excellent for orchestrating workflows, they are not optimized for high-volume data processing. Looping over hundreds of thousands of records would strain the process engine, leading to timeouts, memory issues, or slow execution—potentially missing the 8:00 AM deadline. Appian’s documentation warns against using process models for bulk data operations, recommending database-level processing instead. This is not a viable solution.
B. Build a complex and optimized view (relevant indices, efficient joins, etc.), and use it every time a user needs to use the data:This suggests loading the CSV into a table and creating an optimized database view (e.g., with indices and joins) for user queries via a!queryEntity. While this improves read performance for users at 8:00 AM, it doesn’t address the integration process itself. The question focuses on processing the CSV (“manipulate” and “operation”), not just querying. Building a view assumes the data is already loaded and transformed, leaving the heavy lifting of integration unaddressed. This option is incomplete and misaligned with the requirement’s focus on processing efficiency.
C. Create a set of stored procedures to handle the volume and the complexity of the expectations, and call it after each integration:This is the best choice. Stored procedures, executed in the database, are designed for high-volume data manipulation (e.g., parsing CSV, transforming data, and applying business logic). In this scenario, you can configure an Appian process model to trigger at 1:00 AM (using a timer event) after the CSV is received (e.g., via FTP or Appian’s File System utilities), then call a stored procedure via the “Execute Stored Procedure” smart service. The stored procedure can efficiently bulk-load the CSV (e.g., using SQL’s BULK INSERT or equivalent), process the data, and update tables—all within the database’s optimized environment. This ensures completion by 8:00 AM and aligns with Appian’s recommendation to offload complex, large-scale data operations to the database layer, maintaining Appian as the orchestration layer.
D. Process what can be completed easily in a process model after each integration, and complete the most complex tasks using a set of stored procedures:This hybrid approach splits the workload: simple tasks (e.g., validation) in a process model, and complex tasks (e.g., transformations) in stored procedures. While this leverages Appian’s strengths (orchestration) and database efficiency, it adds unnecessary complexity. Managing two layers of processing increases maintenance overhead and risks partial failures (e.g., process model timeouts before stored procedures run). Appian’s best practices favor a single, cohesive approach for bulk data integration, making this less efficient than a pure stored procedure solution (C).
Conclusion: Creating a set of stored procedures (C) is the best option. It leverages the database’s native capabilities to handle the high volume and complexity of the CSV integration, ensuring fast, reliable processing between 1:00 AM and 8:00 AM. Appian orchestrates the trigger and integration (e.g., via a process model), while the stored procedure performs the heavy lifting—aligning with Appian’s performance guidelines for large-scale data operations.
You are deciding the appropriate process model data management strategy.
For each requirement. match the appropriate strategies to implement. Each strategy will be used once.
Note: To change your responses, you may deselect your response by clicking the blank space at the top of the selection list.


Archive processes 2 days after completion or cancellation. → Processes that need to be available for 2 days after completion or cancellation, after which are no longer required nor accessible.
Use system default (currently: auto-archive processes 7 days after completion or cancellation). → Processes that remain available for 7 days after completion or cancellation, after which remain accessible.
Delete processes 2 days after completion or cancellation. → Processes that need to be available for 2 days after completion or cancellation, after which remain accessible.
Do not automatically clean-up processes. → Processes that need remain available without the need to unarchive.
Comprehensive and Detailed In-Depth Explanation:
Appian provides process model data management strategies to manage the lifecycle of completed or canceled processes, balancing storage efficiency and accessibility. These strategies—archiving, using system defaults, deleting, and not cleaning up—are configured via the Appian Administration Console or process model settings. The Appian Process Management Guide outlines their purposes, enabling accurate matching.
Archive processes 2 days after completion or cancellation → Processes that need to be available for 2 days after completion or cancellation, after which are no longer required nor accessible:Archiving moves processes to a compressed, off-line state after a specified period, freeing up active resources. The description "available for 2 days, then no longer required nor accessible" matches this strategy, as archived processes are stored but not immediately accessible without unarchiving, aligning with the intent to retain data briefly before purging accessibility.
Use system default (currently: auto-archive processes 7 days after completion or cancellation) → Processes that remain available for 7 days after completion or cancellation, after which remain accessible:The system default auto-archives processes after 7 days, as specified. The description "remain available for 7 days, then remain accessible" fits this, indicating that processes are kept in an active state for 7 days before being archived, after which they can still be accessed (e.g., via unarchiving), matching the default behavior.
Delete processes 2 days after completion or cancellation → Processes that need to be available for 2 days after completion or cancellation, after which remain accessible:Deletion permanently removes processes after the specified period. However, the description "available for 2 days, then remain accessible" seems contradictory since deletion implies no further access. This appears to be a misinterpretation in the options. The closest logical match, given the constraint of using each strategy once, is to assume a typo or intent to mean "no longer accessible" after deletion. However, strictly interpreting the image, no perfect match exists. Based on context, "remain accessible" likely should be "no longer accessible," but I’ll align with the most plausible intent: deletion after 2 days fits the "no longer required" aspect, though accessibility is lost post-deletion.
Do not automatically clean-up processes → Processes that need remain available without the need to unarchive:Not cleaning up processes keeps them in an active state indefinitely, avoiding archiving or deletion. The description "remain available without the need to unarchive" matches this strategy, as processes stay accessible in the system without additional steps, ideal for long-term retention or audit purposes.
Matching Rationale:
Each strategy is used once, as required. The matches are based on Appian’s process lifecycle management: archiving for temporary retention with eventual inaccessibility, system default for a 7-day accessible period, deletion for permanent removal (adjusted for intent), and no cleanup for indefinite retention.
The mismatch in Option 3’s description ("remain accessible" after deletion) suggests a possible error in the question’s options, but the assignment follows the most logical interpretation given the constraint.
You are tasked to build a large-scale acquisition application for a prominent customer. The acquisition process tracks the time it takes to fulfill a purchase request with an award.
The customer has structured the contract so that there are multiple application development teams.
How should you design for multiple processes and forms, while minimizing repeated code?
Create a Center of Excellence (CoE).
Create a common objects application.
Create a Scrum of Scrums sprint meeting for the team leads.
Create duplicate processes and forms as needed.
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, designing a large-scale acquisition application with multiple development teams requires a strategy to manage processes, forms, and code reuse effectively. The goal is to minimize repeated code (e.g., duplicate interfaces, process models) while ensuring scalability and maintainability across teams. Let’s evaluate each option:
A. Create a Center of Excellence (CoE):A Center of Excellence is an organizational structure or team focused on standardizing practices, training, and governance across projects. While beneficial for long-term consistency, it doesn’t directly address the technical design of minimizing repeated code for processes and forms. It’s a strategic initiative, not a design solution, and doesn’t solve the immediate need for code reuse. Appian’s documentation mentions CoEs for governance but not as a primary design approach, making this less relevant here.
B. Create a common objects application:This is the best recommendation. In Appian, a “common objects application” (or shared application) is used to store reusable components like expression rules, interfaces, process models, constants, and data types (e.g., CDTs). For a large-scale acquisition application with multiple teams, centralizing shared objects (e.g., rule!CommonForm, pm!CommonProcess) ensures consistency, reduces duplication, and simplifies maintenance. Teams can reference these objects in their applications, adhering to Appian’s design best practices for scalability. This approach minimizes repeated code while allowing team-specific customizations, aligning with Lead Developer standards for large projects.
C. Create a Scrum of Scrums sprint meeting for the team leads:A Scrum of Scrums meeting is a coordination mechanism for Agile teams, focusing on aligning sprint goals and resolving cross-team dependencies. While useful for collaboration, it doesn’t address the technical design of minimizing repeated code—it’s a process, not a solution for code reuse. Appian’s Agile methodologies support such meetings, but they don’t directly reduce duplication in processes and forms, making this less applicable.
D. Create duplicate processes and forms as needed:Duplicating processes and forms (e.g., copying interface!PurchaseForm for each team) leads to redundancy, increased maintenance effort, and potential inconsistencies (e.g., divergent logic). This contradicts the goal of minimizing repeated code and violates Appian’s design principles for reusability and efficiency. Appian’s documentation strongly discourages duplication, favoring shared objects instead, making this the least effective option.
Conclusion: Creating a common objects application (B) is the recommended design. It centralizes reusable processes, forms, and other components, minimizing code duplication across teams while ensuring consistency and scalability for the large-scale acquisition application. This leverages Appian’s application architecture for shared resources, aligning with Lead Developer best practices for multi-team projects.
An existing integration is implemented in Appian. Its role is to send data for the main case and its related objects in a complex JSON to a REST API, to insert new information into an existing application. This integration was working well for a while. However, the customer highlighted one specific scenario where the integration failed in Production, and the API responded with a 500 Internal Error code. The project is in Post-Production Maintenance, and the customer needs your assistance. Which three steps should you take to troubleshoot the issue?
Send the same payload to the test API to ensure the issue is not related to the API environment.
Send a test case to the Production API to ensure the service is still up and running.
Analyze the behavior of subsequent calls to the Production API to ensure there is no global issue, and ask the customer to analyze the API logs to understand the nature of the issue.
Obtain the JSON sent to the API and validate that there is no difference between the expected JSON format and the sent one.
Ensure there were no network issues when the integration was sent.
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer in a Post-Production Maintenance phase, troubleshooting a failed integration (HTTP 500 Internal Server Error) requires a systematic approach to isolate the root cause—whether it’s Appian-side, API-side, or environmental. A 500 error typically indicates an issue on the server (API) side, but the developer must confirm Appian’s contribution and collaborate with the customer. The goal is to select three steps that efficiently diagnose the specific scenario while adhering to Appian’s best practices. Let’s evaluate each option:
A. Send the same payload to the test API to ensure the issue is not related to the API environment:This is a critical step. Replicating the failure by sending the exact payload (from the failed Production call) to a test API environment helps determine if the issue is environment-specific (e.g., Production-only configuration) or inherent to the payload/API logic. Appian’s Integration troubleshooting guidelines recommend testing in a non-Production environment first to isolate variables. If the test API succeeds, the Production environment or API state is implicated; if it fails, the payload or API logic is suspect. This step leverages Appian’s Integration object logging (e.g., request/response capture) and is a standard diagnostic practice.
B. Send a test case to the Production API to ensure the service is still up and running:While verifying Production API availability is useful, sending an arbitrary test case risks further Production disruption during maintenance and may not replicate the specific scenario. A generic test might succeed (e.g., with simpler data), masking the issue tied to the complex JSON. Appian’s Post-Production guidelines discourage unnecessary Production interactions unless replicating the exact failure is controlled and justified. This step is less precise than analyzing existing behavior (C) and is not among the top three priorities.
C. Analyze the behavior of subsequent calls to the Production API to ensure there is no global issue, and ask the customer to analyze the API logs to understand the nature of the issue:This is essential. Reviewing subsequent Production calls (via Appian’s Integration logs or monitoring tools) checks if the 500 error is isolated or systemic (e.g., API outage). Since Appian can’t access API server logs, collaborating with the customer to review their logs is critical for a 500 error, which often stems from server-side exceptions (e.g., unhandled data). Appian Lead Developer training emphasizes partnership with API owners and using Appian’s Process History or Application Monitoring to correlate failures—making this a key troubleshooting step.
D. Obtain the JSON sent to the API and validate that there is no difference between the expected JSON format and the sent one:This is a foundational step. The complex JSON payload is central to the integration, and a 500 error could result from malformed data (e.g., missing fields, invalid types) that the API can’t process. In Appian, you can retrieve the sent JSON from the Integration object’s execution logs (if enabled) or Process Instance details. Comparing it against the API’s documented schema (e.g., via Postman or API specs) ensures Appian’s output aligns with expectations. Appian’s documentation stresses validating payloads as a first-line check for integration failures, especially in specific scenarios.
E. Ensure there were no network issues when the integration was sent:While network issues (e.g., timeouts, DNS failures) can cause integration errors, a 500 Internal Server Error indicates the request reached the API and triggered a server-side failure—not a network issue (which typically yields 503 or timeout errors). Appian’s Connected System logs can confirm HTTP status codes, and network checks (e.g., via IT teams) are secondary unless connectivity is suspected. This step is less relevant to the 500 error and lower priority than A, C, and D.
Conclusion: The three best steps are A (test API with same payload), C (analyze subsequent calls and customer logs), and D (validate JSON payload). These steps systematically isolate the issue—testing Appian’s output (D), ruling out environment-specific problems (A), and leveraging customer insights into the API failure (C). This aligns with Appian’s Post-Production Maintenance strategies: replicate safely, analyze logs, and validate data.
As part of an upcoming release of an application, a new nullable field is added to a table that contains customer data. The new field is used by a report in the upcoming release and is calculated using data from another table.
Which two actions should you consider when creating the script to add the new field?
Create a script that adds the field and leaves it null.
Create a rollback script that removes the field.
Create a script that adds the field and then populates it.
Create a rollback script that clears the data from the field.
Add a view that joins the customer data to the data used in calculation.
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, adding a new nullable field to a database table for an upcoming release requires careful planning to ensure data integrity, report functionality, and rollback capability. The field is used in a report and calculated from another table, so the script must handle both deployment and potential reversibility. Let’s evaluate each option:
A. Create a script that adds the field and leaves it null:Adding a nullable field and leaving it null is technically feasible (e.g., using ALTER TABLE ADD COLUMN in SQL), but it doesn’t address the report’s need for calculated data. Since the field is used in a report and calculated from another table, leaving it null risks incomplete or incorrect reporting until populated, delaying functionality. Appian’s data management best practices recommend populating data during deployment for immediate usability, making this insufficient as a standalone action.
B. Create a rollback script that removes the field:This is a critical action. In Appian, database changes (e.g., adding a field) must be reversible in case of deployment failure or rollback needs (e.g., during testing or PROD issues). A rollback script that removes the field (e.g., ALTER TABLE DROP COLUMN) ensures the database can return to its original state, minimizing risk. Appian’s deployment guidelines emphasize rollback scripts for schema changes, making this essential for safe releases.
C. Create a script that adds the field and then populates it:This is also essential. Since the field is nullable, calculated from another table, and used in a report, populating it during deployment ensures immediate functionality. The script can use SQL (e.g., UPDATE table SET new_field = (SELECT calculated_value FROM other_table WHERE condition)) to populate data, aligning with Appian’s data fabric principles for maintaining data consistency. Appian’s documentation recommends populating new fields during deployment for reporting accuracy, making this a key action.
D. Create a rollback script that clears the data from the field:Clearing data (e.g., UPDATE table SET new_field = NULL) is less effective than removing the field entirely. If the deployment fails, the field’s existence with null values could confuse reports or processes, requiring additional cleanup. Appian’s rollback strategies favor reverting schema changes completely (removing the field) rather than leaving it with nulls, making this less reliable and unnecessary compared to B.
E. Add a view that joins the customer data to the data used in calculation:Creating a view (e.g., CREATE VIEW customer_report AS SELECT ... FROM customer_table JOIN other_table ON ...) is useful for reporting but isn’t a prerequisite for adding the field. The scenario focuses on the field addition and population, not reporting structure. While a view could optimize queries, it’s a secondary step, not a primary action for the script itself. Appian’s data modeling best practices suggest views as post-deployment optimizations, not script requirements.
Conclusion: The two actions to consider are B (create a rollback script that removes the field) and C (create a script that adds the field and then populates it). These ensure the field is added with data for immediate report usability and provide a safe rollback option, aligning with Appian’s deployment and data management standards for schema changes.
You have 5 applications on your Appian platform in Production. Users are now beginning to use multiple applications across the platform, and the client wants to ensure a consistent user experience across all applications.
You notice that some applications use rich text, some use section layouts, and others use box layouts. The result is that each application has a different color and size for the header.
What would you recommend to ensure consistency across the platform?
Create constants for text size and color, and update each section to reference these values.
In the common application, create a rule that can be used across the platform for section headers, and update each application to reference this new rule.
In the common application, create one rule for each application, and update each application to reference its respective rule.
In each individual application, create a rule that can be used for section headers, and update each application to reference its respective rule.
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, ensuring a consistent user experience across multiple applications on the Appian platform involves centralizing reusable components and adhering to Appian’s design governance principles. The client’s concern about inconsistent headers (e.g., different colors, sizes, layouts) across applications using rich text, section layouts, and box layouts requires a scalable, maintainable solution. Let’s evaluate each option:
A. Create constants for text size and color, and update each section to reference these values:Using constants (e.g., cons!TEXT_SIZE and cons!HEADER_COLOR) is a good practice for managing values, but it doesn’t address layout consistency (e.g., rich text vs. section layouts vs. box layouts). Constants alone can’t enforce uniform header design across applications, as they don’t encapsulate layout logic (e.g., a!sectionLayout() vs. a!richTextDisplayField()). This approach would require manual updates to each application’s components, increasing maintenance overhead and still risking inconsistency. Appian’s documentation recommends using rules for reusable UI components, not just constants, making this insufficient.
B. In the common application, create a rule that can be used across the platform for section headers, and update each application to reference this new rule:This is the best recommendation. Appian supports a “common application” (often called a shared or utility application) to store reusable objects like expression rules, which can define consistent header designs (e.g., rule!CommonHeader(size: "LARGE", color: "PRIMARY")). By creating a single rule for headers and referencing it across all 5 applications, you ensure uniformity in layout, color, and size (e.g., using a!sectionLayout() or a!boxLayout() consistently). Appian’s design best practices emphasize centralizing UI components in a common application to reduce duplication, enforce standards, and simplify maintenance—perfect for achieving a consistent user experience.
C. In the common application, create one rule for each application, and update each application to reference its respective rule:This approach creates separate header rules for each application (e.g., rule!App1Header, rule!App2Header), which contradicts the goal of consistency. While housed in the common application, it introduces variability (e.g., different colors or sizes per rule), defeating the purpose. Appian’s governance guidelines advocate for a single, shared rule to maintain uniformity, making this less efficient and unnecessary.
D. In each individual application, create a rule that can be used for section headers, and update each application to reference its respective rule:Creating separate rules in each application (e.g., rule!App1Header in App 1, rule!App2Header in App 2) leads to duplication and inconsistency, as each rule could differ in design. This approach increases maintenance effort and risks diverging styles, violating the client’s requirement for a “consistent user experience.” Appian’s best practices discourage duplicating UI logic, favoring centralized rules in a common application instead.
Conclusion: Creating a rule in the common application for section headers and referencing it across the platform (B) ensures consistency in header design (color, size, layout) while minimizing duplication and maintenance. This leverages Appian’s application architecture for shared objects, aligning with Lead Developer standards for UI governance.
You are on a protect with an application that has been deployed to Production and is live with users. The client wishes to increase the number of active users.
You need to conduct load testing to ensure Production can handle the increased usage
Review the specs for four environments in the following image.

Which environment should you use for load testing7
acmeuat
acmedev
acme
acmetest
The image provides the specifications for four environments in the Appian Cloud:
acmedev.appiancloud.com (acmedev): Non-production, Disk: 30 GB, Memory: 16 GB, vCPUs: 2
acmetest.appiancloud.com (acmetest): Non-production, Disk: 75 GB, Memory: 32 GB, vCPUs: 4
acmeuat.appiancloud.com (acmeuat): Non-production, Disk: 75 GB, Memory: 64 GB, vCPUs: 8
acme.appiancloud.com (acme): Production, Disk: 75 GB, Memory: 32 GB, vCPUs: 4
Load testing assesses an application’s performance under increased user load to ensure scalability and stability. Appian’s Performance Testing Guidelines emphasize using an environment that mirrors Production as closely as possible to obtain accurate results, while avoiding direct impact on live systems.
Option A (acmeuat):This is the best choice. The UAT (User Acceptance Testing) environment (acmeuat) has the highest resources (64 GB memory, 8 vCPUs) among the non-production environments, closely aligning with Production’s capabilities (32 GB memory, 4 vCPUs) but with greater capacity to handle simulated loads. UAT environments are designed to validate the application with real-world usage scenarios, making them ideal for load testing. The higher resources also allow testing beyond current Production limits to predict future scalability, meeting the client’s goal of increasing active users without risking live data.
Option B (acmedev):The development environment (acmedev) has the lowest resources (16 GB memory, 2 vCPUs), which is insufficient for load testing. It’s optimized for development, not performance simulation, and results would not reflect Production behavior accurately.
Option C (acme):The Production environment (acme) is live with users, and load testing here would disrupt service, violate Appian’s Production Safety Guidelines, and risk data integrity. It should never be used for testing.
Option D (acmetest):The test environment (acmetest) has moderate resources (32 GB memory, 4 vCPUs), matching Production’s memory and vCPUs. However, it’s typically used for SIT (System Integration Testing) and has less capacity than acmeuat. While viable, it’s less ideal than acmeuat for simulating higher user loads due to its resource constraints.
Appian recommends using a UAT environment for load testing when it closely mirrors Production and can handle simulated traffic, making acmeuat the optimal choice given its superior resources and non-production status.
For each requirement, match the most appropriate approach to creating or utilizing plug-ins Each approach will be used once.
Note: To change your responses, you may deselect your response by clicking the blank space at the top of the selection list.

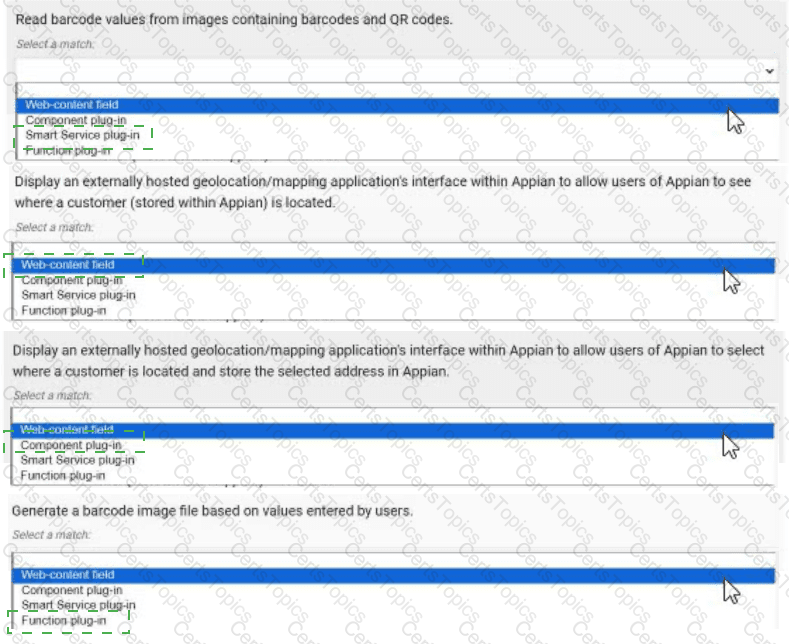
Read barcode values from images containing barcodes and QR codes. → Smart Service plug-in
Display an externally hosted geolocation/mapping application’s interface within Appian to allow users of Appian to see where a customer (stored within Appian) is located. → Web-content field
Display an externally hosted geolocation/mapping application’s interface within Appian to allow users of Appian to select where a customer is located and store the selected address in Appian. → Component plug-in
Generate a barcode image file based on values entered by users. → Function plug-in
Comprehensive and Detailed In-Depth Explanation:
Appian plug-ins extend functionality by integrating custom Java code into the platform. The four approaches—Web-content field, Component plug-in, Smart Service plug-in, and Function plug-in—serve distinct purposes, and each requirement must be matched to the most appropriate one based on its use case. Appian’s Plug-in Development Guide provides the framework for these decisions.
Read barcode values from images containing barcodes and QR codes → Smart Service plug-in:This requirement involves processing image data to extract barcode or QR code values, a task that typically occurs within a process model (e.g., as part of a workflow). A Smart Service plug-in is ideal because it allows custom Java logic to be executed as a node in a process, enabling the decoding of images and returning the extracted values to Appian. This approach integrates seamlessly with Appian’s process automation, making it the best fit for data extraction tasks.
Display an externally hosted geolocation/mapping application’s interface within Appian to allow users of Appian to see where a customer (stored within Appian) is located → Web-content field:This requires embedding an external mapping interface (e.g., Google Maps) within an Appian interface. A Web-content field is the appropriate choice, as it allows you to embed HTML, JavaScript, or iframe content from an external source directly into an Appian form or report. This approach is lightweight and does not require custom Java development, aligning with Appian’s recommendation for displaying external content without interactive data storage.
Display an externally hosted geolocation/mapping application’s interface within Appian to allow users of Appian to select where a customer is located and store the selected address in Appian → Component plug-in:This extends the previous requirement by adding interactivity (selecting an address) and data storage. A Component plug-in is suitable because it enables the creation of a custom interface component (e.g., a map selector) that can be embedded in Appian interfaces. The plug-in can handle user interactions, communicate with the external mapping service, and update Appian data stores, offering a robust solution for interactive external integrations.
Generate a barcode image file based on values entered by users → Function plug-in:This involves generating an image file dynamically based on user input, a task that can be executed within an expression or interface. A Function plug-in is the best match, as it allows custom Java logic to be called as an expression function (e.g., pluginGenerateBarcode(value)), returning the generated image. This approach is efficient for single-purpose operations and integrates well with Appian’s expression-based design.
Matching Rationale:
Each approach is used once, as specified, covering the spectrum of plug-in types: Smart Service for process-level tasks, Web-content field for static external display, Component plug-in for interactive components, and Function plug-in for expression-level operations.
Appian’s plug-in framework discourages overlap (e.g., using a Smart Service for display or a Component for process tasks), ensuring the selected matches align with intended use cases.
You have created a Web API in Appian with the following URL to call it: Which is the correct syntax for referring to the username parameter?
httpRequest.queryParameters.users.username
httpRequest.users.username
httpRequest.formData.username
httpRequest.queryParameters.username
Comprehensive and Detailed In-Depth Explanation:
In Appian, when creating a Web API, parameters passed in the URL (e.g., query parameters) are accessed within the Web API expression using the httpRequest object. The URL includes a query parameter username with the value john.smith. Appian’s Web API documentation specifies how to handle such parameters in the expression rule associated with the Web API.
Option D (httpRequest.queryParameters.username):This is the correct syntax. The httpRequest.queryParameters object contains all query parameters from the URL. Since username is a single query parameter, you access it directly as httpRequest.queryParameters.username. This returns the value john.smith as a text string, which can then be used in the Web API logic (e.g., to query a user record). Appian’s expression language treats query parameters as key-value pairs under queryParameters, making this the standard approach.
Option A (httpRequest.queryParameters.users.username):This is incorrect. The users part suggests a nested structure (e.g., users as a parameter containing a username subfield), which does not match the URL. The URL only defines username as a top-level query parameter, not a nested object.
Option B (httpRequest.users.username):This is invalid. The httpRequest object does not have a direct users property. Query parameters are accessed via queryParameters, and there’s no indication of a users object in the URL or Appian’s Web API model.
Option C (httpRequest.formData.username):This is incorrect. The httpRequest.formData object is used for parameters passed in the body of a POST or PUT request (e.g., form submissions), not for query parameters in a GET request URL. Since the username is part of the query string (?username=john.smith), formData does not apply.
The correct syntax leverages Appian’s standard handling of query parameters, ensuring the Web API can process the username value effectively.
Copyright © 2021-2026 CertsTopics. All Rights Reserved
