A company wants to improve its customer retention ML model. The current model has 85% accuracy and a new model shows 87% accuracy in testing. The company wants to validate the new model’s performance in production.
Which solution will meet these requirements?
A company needs to create a central catalog for all the company ' s ML models. The models are in AWS accounts where the company developed the models initially. The models are hosted in Amazon Elastic Container Registry (Amazon ECR) repositories.
Which solution will meet these requirements?
A company has a large collection of chat recordings from customer interactions after a product release. An ML engineer needs to create an ML model to analyze the chat data. The ML engineer needs to determine the success of the product by reviewing customer sentiments about the product.
Which action should the ML engineer take to complete the evaluation in the LEAST amount of time?
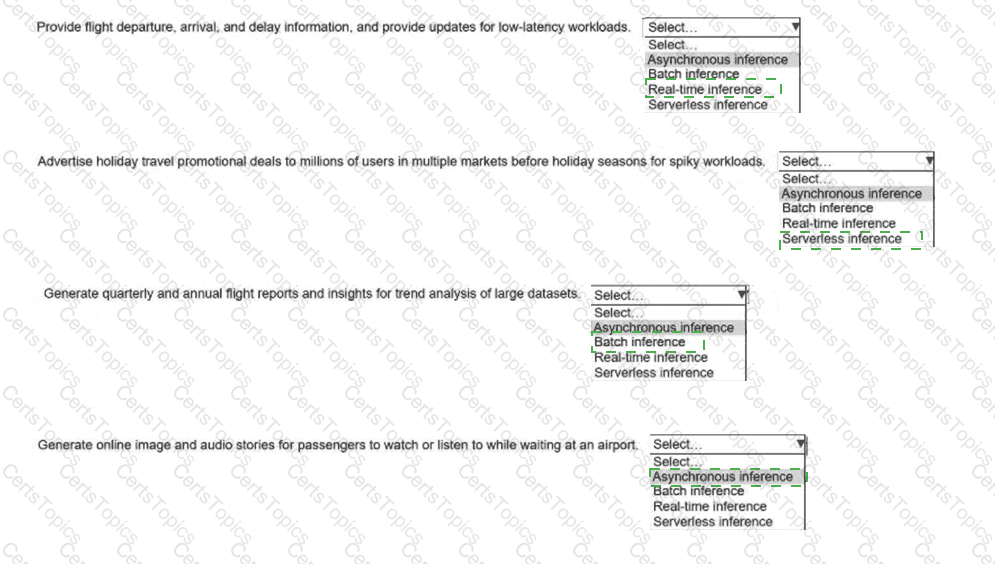
An airline company deploys ML models to one dozen Amazon SageMaker Al inference endpoints. The inference endpoints must be able to handle different types of
workloads in a cost-effective way.
Select the correct inference option from the following list to handle each type of workload. Select each inference option one time. (Select FOUR.)
Asynchronous inference
Batch inference
Real-time inference
Serverless inference

Copyright © 2021-2026 CertsTopics. All Rights Reserved