A company has a conversational AI assistant that sends requests through Amazon Bedrock to an Anthropic Claude large language model (LLM). Users report that when they ask similar questions multiple times, they sometimes receive different answers. An ML engineer needs to improve the responses to be more consistent and less random.
Which solution will meet these requirements?
An ML engineer is training an ML model to identify medical patients for disease screening. The tabular dataset for training contains 50,000 patient records: 1,000 with the disease and 49,000 without the disease.
The ML engineer splits the dataset into a training dataset, a validation dataset, and a test dataset.
What should the ML engineer do to transform the data and make the data suitable for training?
A company is using an Amazon Redshift database as its single data source. Some of the data is sensitive.
A data scientist needs to use some of the sensitive data from the database. An ML engineer must give the data scientist access to the data without transforming the source data and without storing anonymized data in the database.
Which solution will meet these requirements with the LEAST implementation effort?
An ML engineer is evaluating several ML models and must choose one model to use in production. The cost of false negative predictions by the models is much higher than the cost of false positive predictions.
Which metric finding should the ML engineer prioritize the MOST when choosing the model?
A company wants to improve its customer retention ML model. The current model has 85% accuracy and a new model shows 87% accuracy in testing. The company wants to validate the new model’s performance in production.
Which solution will meet these requirements?
A company needs to create a central catalog for all the company ' s ML models. The models are in AWS accounts where the company developed the models initially. The models are hosted in Amazon Elastic Container Registry (Amazon ECR) repositories.
Which solution will meet these requirements?
A company has a large collection of chat recordings from customer interactions after a product release. An ML engineer needs to create an ML model to analyze the chat data. The ML engineer needs to determine the success of the product by reviewing customer sentiments about the product.
Which action should the ML engineer take to complete the evaluation in the LEAST amount of time?
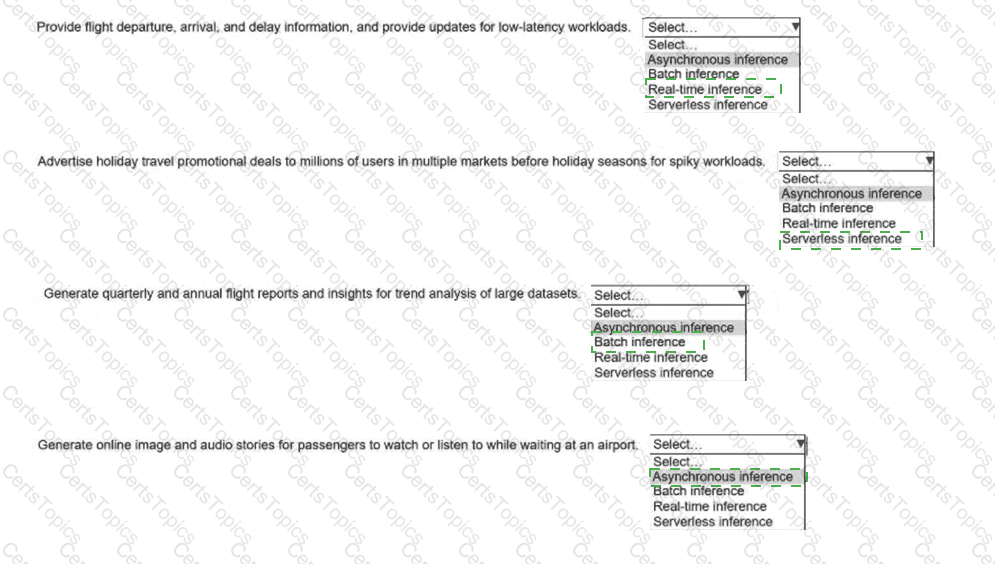
An airline company deploys ML models to one dozen Amazon SageMaker Al inference endpoints. The inference endpoints must be able to handle different types of
workloads in a cost-effective way.
Select the correct inference option from the following list to handle each type of workload. Select each inference option one time. (Select FOUR.)
Asynchronous inference
Batch inference
Real-time inference
Serverless inference

An ML engineer needs to use an ML model to predict the price of apartments in a specific location.
Which metric should the ML engineer use to evaluate the model’s performance?
A company has an ML model in Amazon SageMaker AI. An ML engineer needs to implement a monitoring solution to automatically detect changes in the input data distribution of model features.
Which solution will meet this requirement with the LEAST operational overhead?
An ML engineer wants to re-train an XGBoost model at the end of each month. A data team prepares the training data. The training dataset is a few hundred megabytes in size. When the data is ready, the data team stores the data as a new file in an Amazon S3 bucket.
The ML engineer needs a solution to automate this pipeline. The solution must register the new model version in Amazon SageMaker Model Registry within 24 hours.
Which solution will meet these requirements?
An ML model is deployed in production. The model has performed well and has met its metric thresholds for months.
An ML engineer who is monitoring the model observes a sudden degradation. The performance metrics of the model are now below the thresholds.
What could be the cause of the performance degradation?
An ML engineer is designing an AI-powered traffic management system. The system must use near real-time inference to predict congestion and prevent collisions.
The system must also use batch processing to perform historical analysis of predictions over several hours to improve the model. The inference endpoints must scale automatically to meet demand.
Which combination of solutions will meet these requirements? (Select TWO.)
A company is building a deep learning model on Amazon SageMaker. The company uses a large amount of data as the training dataset. The company needs to optimize the model ' s hyperparameters to minimize the loss function on the validation dataset.
Which hyperparameter tuning strategy will accomplish this goal with the LEAST computation time?
An ML engineer is using an Amazon SageMaker AI shadow test to evaluate a new model that is hosted on a SageMaker AI endpoint. The shadow test requires significant GPU resources for high performance. The production variant currently runs on a less powerful instance type.
The ML engineer needs to configure the shadow test to use a higher performance instance type for a shadow variant. The solution must not affect the instance type of the production variant.
Which solution will meet these requirements?
An ML engineer is setting up a CI/CD pipeline for an ML workflow in Amazon SageMaker AI. The pipeline must automatically retrain, test, and deploy a model whenever new data is uploaded to an Amazon S3 bucket. New data files are approximately 10 GB in size. The ML engineer also needs to track model versions for auditing.
Which solution will meet these requirements?
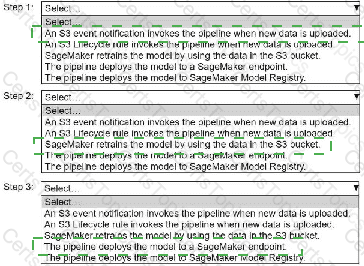
A company wants to host an ML model on Amazon SageMaker. An ML engineer is configuring a continuous integration and continuous delivery (Cl/CD) pipeline in AWS CodePipeline to deploy the model. The pipeline must run automatically when new training data for the model is uploaded to an Amazon S3 bucket.
Select and order the pipeline ' s correct steps from the following list. Each step should be selected one time or not at all. (Select and order three.)
• An S3 event notification invokes the pipeline when new data is uploaded.
• S3 Lifecycle rule invokes the pipeline when new data is uploaded.
• SageMaker retrains the model by using the data in the S3 bucket.
• The pipeline deploys the model to a SageMaker endpoint.
• The pipeline deploys the model to SageMaker Model Registry.

A company wants to deploy an Amazon SageMaker AI model that can queue requests. The model needs to handle payloads of up to 1 GB that take up to 1 hour to process. The model must return an inference for each request. The model also must scale down when no requests are available to process.
Which inference option will meet these requirements?
A company needs an AWS solution that will automatically create versions of ML models as the models are created. Which solution will meet this requirement?
A company is building a near real-time data analytics application to detect anomalies and failures for industrial equipment. The company has thousands of IoT sensors that send data every 60 seconds. When new versions of the application are released, the company wants to ensure that application code bugs do not prevent the application from running.
Which solution will meet these requirements?
A company has implemented a data ingestion pipeline for sales transactions from its ecommerce website. The company uses Amazon Data Firehose to ingest data into Amazon OpenSearch Service. The buffer interval of the Firehose stream is set for 60 seconds. An OpenSearch linear model generates real-time sales forecasts based on the data and presents the data in an OpenSearch dashboard.
The company needs to optimize the data ingestion pipeline to support sub-second latency for the real-time dashboard.
Which change to the architecture will meet these requirements?
A company is creating an ML model to identify defects in a product. The company has gathered a dataset and has stored the dataset in TIFF format in Amazon S3. The dataset contains 200 images in which the most common defects are visible. The dataset also contains 1,800 images in which there is no defect visible.
An ML engineer trains the model and notices poor performance in some classes. The ML engineer identifies a class imbalance problem in the dataset.
What should the ML engineer do to solve this problem?
A company wants to migrate ML models from an on-premises environment to Amazon SageMaker AI. The models are based on the PyTorch algorithm. The company needs to reuse its existing custom scripts as much as possible.
Which SageMaker AI feature should the company use?
Case study
An ML engineer is developing a fraud detection model on AWS. The training dataset includes transaction logs, customer profiles, and tables from an on-premises MySQL database. The transaction logs and customer profiles are stored in Amazon S3.
The dataset has a class imbalance that affects the learning of the model ' s algorithm. Additionally, many of the features have interdependencies. The algorithm is not capturing all the desired underlying patterns in the data.
The training dataset includes categorical data and numerical data. The ML engineer must prepare the training dataset to maximize the accuracy of the model.
Which action will meet this requirement with the LEAST operational overhead?
An ML engineer is analyzing a classification dataset before training a model in Amazon SageMaker AI. The ML engineer suspects that the dataset has a significant imbalance between class labels that could lead to biased model predictions. To confirm class imbalance, the ML engineer needs to select an appropriate pre-training bias metric.
Which metric will meet this requirement?
An ML engineer is using Amazon SageMaker to train a deep learning model that requires distributed training. After some training attempts, the ML engineer observes that the instances are not performing as expected. The ML engineer identifies communication overhead between the training instances.
What should the ML engineer do to MINIMIZE the communication overhead between the instances?
A company has trained and deployed an ML model by using Amazon SageMaker. The company needs to implement a solution to record and monitor all the API call events for the SageMaker endpoint. The solution also must provide a notification when the number of API call events breaches a threshold.
Use SageMaker Debugger to track the inferences and to report metrics. Create a custom rule to provide a notification when the threshold is breached.
Which solution will meet these requirements?
A company is developing an ML model by using Amazon SageMaker AI. The company must monitor bias in the model and display the results on a dashboard. An ML engineer creates a bias monitoring job.
How should the ML engineer capture bias metrics to display on the dashboard?
An advertising company uses AWS Lake Formation to manage a data lake. The data lake contains structured data and unstructured data. The company ' s ML engineers are assigned to specific advertisement campaigns.
The ML engineers must interact with the data through Amazon Athena and by browsing the data directly in an Amazon S3 bucket. The ML engineers must have access to only the resources that are specific to their assigned advertisement campaigns.
Which solution will meet these requirements in the MOST operationally efficient way?
A company uses a training job on Amazon SageMaker Al to train a neural network. The job first trains a model and then evaluates the model ' s performance ag
test dataset. The company uses the results from the evaluation phase to decide if the trained model will go to production.
The training phase takes too long. The company needs solutions that can shorten training time without decreasing the model ' s final performance.
Select the correct solutions from the following list to meet the requirements for each description. Select each solution one time or not at all. (Select THREE.)
. Change the epoch count.
. Choose an Amazon EC2 Spot Fleet.
· Change the batch size.
. Use early stopping on the training job.
· Use the SageMaker Al distributed data parallelism (SMDDP) library.
. Stop the training job.

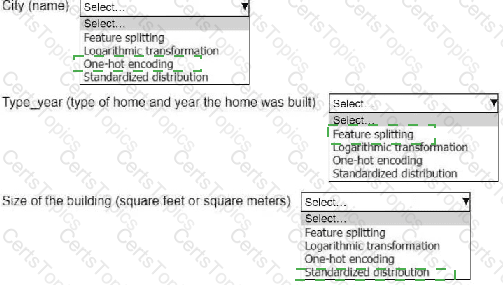
An ML engineer is working on an ML model to predict the prices of similarly sized homes. The model will base predictions on several features The ML engineer will use the following feature engineering techniques to estimate the prices of the homes:
• Feature splitting
• Logarithmic transformation
• One-hot encoding
• Standardized distribution
Select the correct feature engineering techniques for the following list of features. Each feature engineering technique should be selected one time or not at all (Select three.)

A company uses an Amazon SageMaker AI model for real-time inference with auto scaling enabled. During peak usage, new instances launch before existing instances are fully ready, causing inefficiencies and delays.
Which solution will optimize the scaling process without affecting response times?
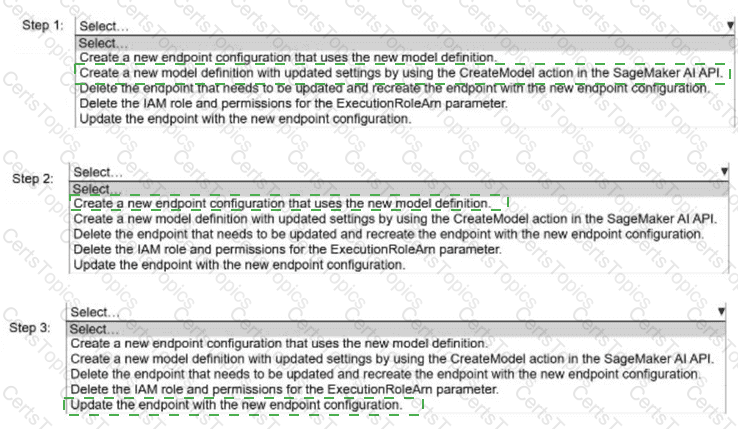
A company needs to update the model definition of an existing Amazon SageMaker Al endpoint.
Select and order the correct steps from the following list to update the model definition settings with the LEAST interruption of inferences. Select each step one time or not
at all. (Select and order THREE.)
Create a new endpoint configuration that uses the new model definition.
Create a new model definition with updated settings by using the CreateModel action in the SageMaker AI API.
Delete the endpoint that needs to be updated and recreate the endpoint with the new endpoint configuration.
Delete the IAM role and permissions for the ExecutionRoleArn parameter.
Update the endpoint with the new endpoint configuration.

An ML engineer normalized training data by using min-max normalization in AWS Glue DataBrew. The ML engineer must normalize production inference data in the same way before passing the data to the model.
Which solution will meet this requirement?
A company is creating an application that will recommend products for customers to purchase. The application will make API calls to Amazon Q Business. The company must ensure that responses from Amazon Q Business do not include the name of the company ' s main competitor.
Which solution will meet this requirement?
An ML engineer wants to deploy a workflow that processes streaming IoT sensor data and periodically retrains ML models. The most recent model versions must be deployed to production.
Which service will meet these requirements?
A company needs to run a batch data-processing job on Amazon EC2 instances. The job will run during the weekend and will take 90 minutes to finish running. The processing can handle interruptions. The company will run the job every weekend for the next 6 months.
Which EC2 instance purchasing option will meet these requirements MOST cost-effectively?
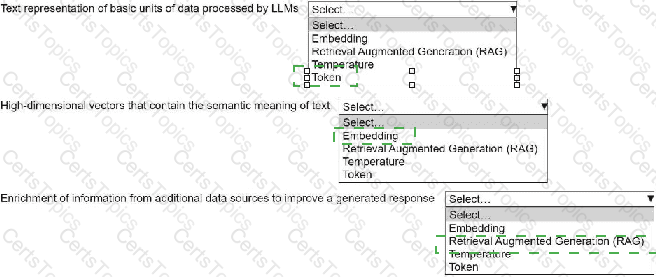
An ML engineer is building a generative AI application on Amazon Bedrock by using large language models (LLMs).
Select the correct generative AI term from the following list for each description. Each term should be selected one time or not at all. (Select three.)
• Embedding
• Retrieval Augmented Generation (RAG)
• Temperature
• Token
An ML engineer needs to use AWS CloudFormation to create an ML model that an Amazon SageMaker endpoint will host.
Which resource should the ML engineer declare in the CloudFormation template to meet this requirement?
A recommendation model uses ML and calls an Amazon SageMaker AI endpoint to get recommendations. An ML engineer must ensure that the model stays available during an expected increase in user traffic.
Which solution will meet these requirements?
A company regularly receives new training data from the vendor of an ML model. The vendor delivers cleaned and prepared data to the company ' s Amazon S3 bucket every 3-4 days.
The company has an Amazon SageMaker pipeline to retrain the model. An ML engineer needs to implement a solution to run the pipeline when new data is uploaded to the S3 bucket.
Which solution will meet these requirements with the LEAST operational effort?
A company is building an enterprise AI platform. The company must catalog models for production, manage model versions, and associate metadata such as training metrics with models. The company needs to eliminate the burden of managing different versions of models.
Which solution will meet these requirements?
A company wants to use large language models (LLMs) supported by Amazon Bedrock to develop a chat interface for internal technical documentation.
The documentation consists of dozens of text files totaling several megabytes and is updated frequently.
Which solution will meet these requirements MOST cost-effectively?
An ML engineer needs to use Amazon SageMaker to fine-tune a large language model (LLM) for text summarization. The ML engineer must follow a low-code no-code (LCNC) approach.
Which solution will meet these requirements?
A company has used Amazon SageMaker to deploy a predictive ML model in production. The company is using SageMaker Model Monitor on the model. After a model update, an ML engineer notices data quality issues in the Model Monitor checks.
What should the ML engineer do to mitigate the data quality issues that Model Monitor has identified?
An ML engineer is building a model to predict house and apartment prices. The model uses three features: Square Meters, Price, and Age of Building. The dataset has 10,000 data rows. The data includes data points for one large mansion and one extremely small apartment.
The ML engineer must perform preprocessing on the dataset to ensure that the model produces accurate predictions for the typical house or apartment.
Which solution will meet these requirements?
An ML engineer is developing a classification model. The ML engineer needs to use custom libraries in processing jobs, training jobs, and pipelines in Amazon SageMaker AI.
Which solution will provide this functionality with the LEAST implementation effort?
A company is developing ML models by using PyTorch and TensorFlow estimators with Amazon SageMaker AI. An ML engineer configures the SageMaker AI estimator and now needs to initiate a training job that uses a training dataset.
Which SageMaker AI SDK method can initiate the training job?
An ML engineer is setting up an Amazon SageMaker AI pipeline for an ML model. The pipeline must automatically initiate a re-training job if any data drift is detected.
How should the ML engineer set up the pipeline to meet this requirement?
A company is developing an ML model to predict customer satisfaction. The company needs to use survey feedback and the past satisfaction level of customers to predict the future satisfaction level of customers.
The dataset includes a column named Feedback that contains long text responses. The dataset also includes a column named Satisfaction Level that contains three distinct values for past customer satisfaction: High, Medium, and Low. The company must apply encoding methods to transform the data in each column.
Which solution will meet these requirements?
A company plans to use Amazon SageMaker AI to build image classification models. The company has 6 TB of training data stored on Amazon FSx for NetApp ONTAP. The file system is in the same VPC as SageMaker AI.
An ML engineer must make the training data accessible to SageMaker AI training jobs.
Which solution will meet these requirements?
A digital media entertainment company needs real-time video content moderation to ensure compliance during live streaming events.
Which solution will meet these requirements with the LEAST operational overhead?
A company runs an Amazon SageMaker AI domain in a public subnet of a newly created VPC. The network is configured properly, and ML engineers can access the SageMaker AI domain.
Recently, the company discovered suspicious traffic to the domain from a specific IP address. The company needs to block traffic from the specific IP address.
Which update to the network configuration will meet this requirement?
A company wants to use large language models (LLMs) that are supported by Amazon Bedrock to develop a chat interface for the company ' s internal technical documentation. The company stores the documentation as dozens of text files that are several megabytes in total size. The company updates the text files often.
Which solution will meet these requirements MOST cost-effectively?
A company launches a feature that predicts home prices. An ML engineer trained a regression model using the SageMaker AI XGBoost algorithm. The model performs well on training data but underperforms on real-world validation data.
Which solution will improve the validation score with the LEAST implementation effort?
A company is using an Amazon S3 bucket to collect data that will be used for ML workflows. The company needs to use AWS Glue DataBrew to clean and normalize the data.
Which solution will meet these requirements?
A travel company has trained hundreds of geographic data models to answer customer questions by using Amazon SageMaker AI. Each model uses its own inferencing endpoint, which has become an operational challenge for the company.
The company wants to consolidate the models ' inferencing endpoints to reduce operational overhead.
Which solution will meet these requirements?
A company has a custom extract, transform, and load (ETL) process that runs on premises. The ETL process is written in the R language and runs for an average of 6 hours. The company wants to migrate the process to run on AWS.
Which solution will meet these requirements?
A company is planning to create several ML prediction models. The training data is stored in Amazon S3. The entire dataset is more than 5 ТВ in size and consists of CSV, JSON, Apache Parquet, and simple text files.
The data must be processed in several consecutive steps. The steps include complex manipulations that can take hours to finish running. Some of the processing involves natural language processing (NLP) transformations. The entire process must be automated.
Which solution will meet these requirements?
A company ' s ML engineer is creating a classification model. The ML engineer explores the dataset and notices a column named day_of_week. The column contains the following values: Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, and Sunday.
Which technique should the ML engineer use to convert this column’s data to binary values?
An ML engineer is setting up a continuous integration and continuous delivery (CI/CD) pipeline for an ML workflow in Amazon SageMaker AI. The pipeline needs to automate model re-training, testing, and deployment whenever new data is uploaded to an Amazon S3 bucket. New data files are approximately 10 GB in size. The ML engineer wants to track model versions for auditing.
Which solution will meet these requirements?
A company has multiple models that are hosted on Amazon SageMaker Al. The models need to be re-trained. The requirements for each model are different, so the company needs to choose different deployment strategies to transfer all requests to a new model.
Select the correct strategy from the following list for each requirement. Select each strategy one time. (Select THREE.)
. Canary traffic shifting
. Linear traffic shifting guardrail
. All at once traffic shifting

A travel company wants to create an ML model to recommend the next airport destination for its users. The company has collected millions of data records about user location, recent search history on the company ' s website, and 2,000 available airports. The data has several categorical features with a target column that is expected to have a high-dimensional sparse matrix.
The company needs to use Amazon SageMaker AI built-in algorithms for the model. An ML engineer converts the categorical features by using one-hot encoding.
Which algorithm should the ML engineer implement to meet these requirements?
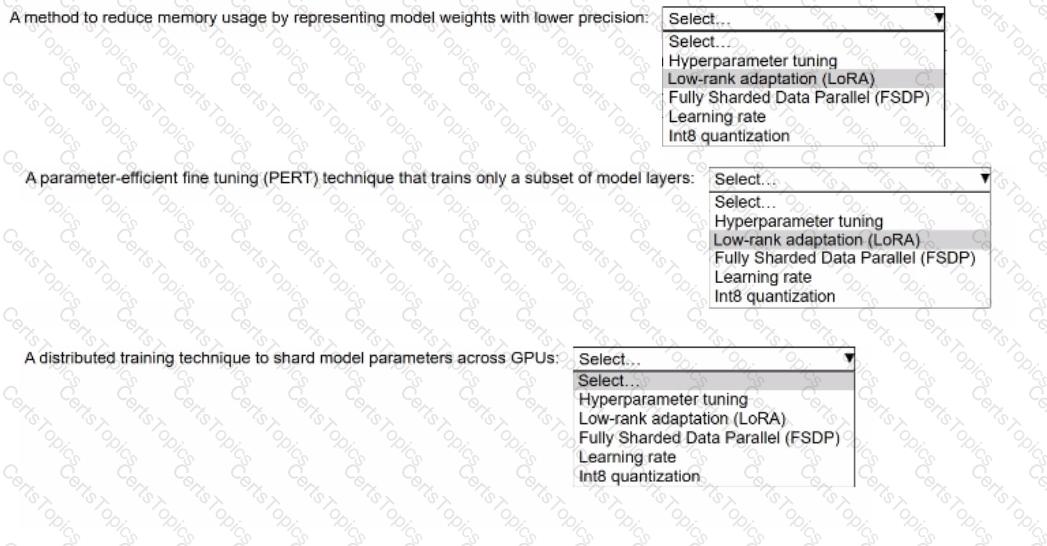
An ML engineer is using Amazon SageMaker JumpStart to fine-tune a Llama 3.2 model for text generation. The ML engineer is using an instruction-based fine-tuning method. The model uses 70 billion parameters.
Select the correct fine-tuning term from the following list to match each description. Select each term one time or not at all. (Select THREE.)
• Hyperparameter tuning
• Low-rank adaptation (LoRA)
• Fully Sharded Data Parallel (FSDP)
• Learning rate
• Int8 quantization
An ML engineer is deploying a generative AI model-based customer support agent that uses Amazon SageMaker AI for inference. The customer support agent must respond to customer questions about topics such as shipping policies, refund processes, and account management. The generative AI model generates one token at a time.
Customers report dissatisfaction with how long the customer support agent takes to generate lengthy responses to questions. The ML engineer must apply an inference optimization technique to improve the performance of the customer support agent.
Which solution will meet this requirement?
A company uses Amazon SageMaker for its ML workloads. The company ' s ML engineer receives a 50 MB Apache Parquet data file to build a fraud detection model. The file includes several correlated columns that are not required.
What should the ML engineer do to drop the unnecessary columns in the file with the LEAST effort?
An ML engineer is tuning an image classification model that shows poor performance on one of two available classes during prediction. Analysis reveals that the images whose class the model performed poorly on represent an extremely small fraction of the whole training dataset.
The ML engineer must improve the model ' s performance.
Which solution will meet this requirement?
A company has a team of data scientists who use Amazon SageMaker notebook instances to test ML models. When the data scientists need new permissions, the company attaches the permissions to each individual role that was created during the creation of the SageMaker notebook instance.
The company needs to centralize management of the team ' s permissions.
Which solution will meet this requirement?
A company has a Retrieval Augmented Generation (RAG) application that uses a vector database to store embeddings of documents. The company must migrate the application to AWS and must implement a solution that provides semantic search of text files. The company has already migrated the text repository to an Amazon S3 bucket.
Which solution will meet these requirements?
A government agency is conducting a national census to assess program needs by area and city. The census form collects approximately 500 responses from each citizen. The agency needs to analyze the data to extract meaningful insights. The agency wants to reduce the dimensions of the high-dimensional data to uncover hidden patterns.
Which solution will meet these requirements?
A company must install a custom script on any newly created Amazon SageMaker AI notebook instances.
Which solution will meet this requirement with the LEAST operational overhead?
A company stores time-series data about user clicks in an Amazon S3 bucket. The raw data consists of millions of rows of user activity every day. ML engineers access the data to develop their ML models.
The ML engineers need to generate daily reports and analyze click trends over the past 3 days by using Amazon Athena. The company must retain the data for 30 days before archiving the data.
Which solution will provide the HIGHEST performance for data retrieval?
Copyright © 2021-2026 CertsTopics. All Rights Reserved