An advertising company uses AWS Lake Formation to manage a data lake. The data lake contains structured data and unstructured data. The company ' s ML engineers are assigned to specific advertisement campaigns.
The ML engineers must interact with the data through Amazon Athena and by browsing the data directly in an Amazon S3 bucket. The ML engineers must have access to only the resources that are specific to their assigned advertisement campaigns.
Which solution will meet these requirements in the MOST operationally efficient way?
A company uses a training job on Amazon SageMaker Al to train a neural network. The job first trains a model and then evaluates the model ' s performance ag
test dataset. The company uses the results from the evaluation phase to decide if the trained model will go to production.
The training phase takes too long. The company needs solutions that can shorten training time without decreasing the model ' s final performance.
Select the correct solutions from the following list to meet the requirements for each description. Select each solution one time or not at all. (Select THREE.)
. Change the epoch count.
. Choose an Amazon EC2 Spot Fleet.
· Change the batch size.
. Use early stopping on the training job.
· Use the SageMaker Al distributed data parallelism (SMDDP) library.
. Stop the training job.

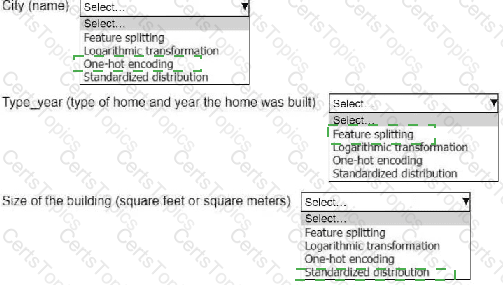
An ML engineer is working on an ML model to predict the prices of similarly sized homes. The model will base predictions on several features The ML engineer will use the following feature engineering techniques to estimate the prices of the homes:
• Feature splitting
• Logarithmic transformation
• One-hot encoding
• Standardized distribution
Select the correct feature engineering techniques for the following list of features. Each feature engineering technique should be selected one time or not at all (Select three.)

A company uses an Amazon SageMaker AI model for real-time inference with auto scaling enabled. During peak usage, new instances launch before existing instances are fully ready, causing inefficiencies and delays.
Which solution will optimize the scaling process without affecting response times?
Copyright © 2021-2026 CertsTopics. All Rights Reserved