A data scientist wants to predict a person's travel destination. The options are:
Branson, Missouri, United States
Mount Kilimanjaro, Tanzania
Disneyland Paris, Paris, France
Sydney Opera House, Sydney, Australia
Which of the following models would best fit this use case?
A data scientist is working with a data set that has ten predictors and wants to use only the predictors that most influence the results. Which of the following models would be the best for the data scientist to use?
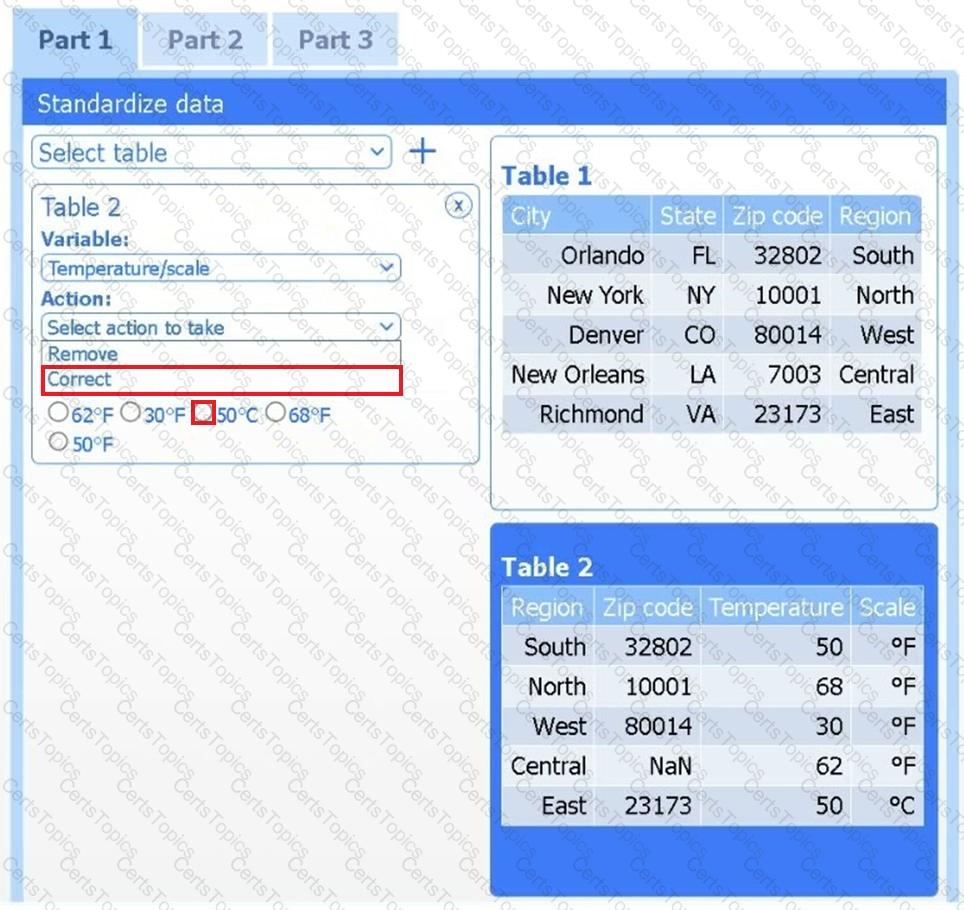
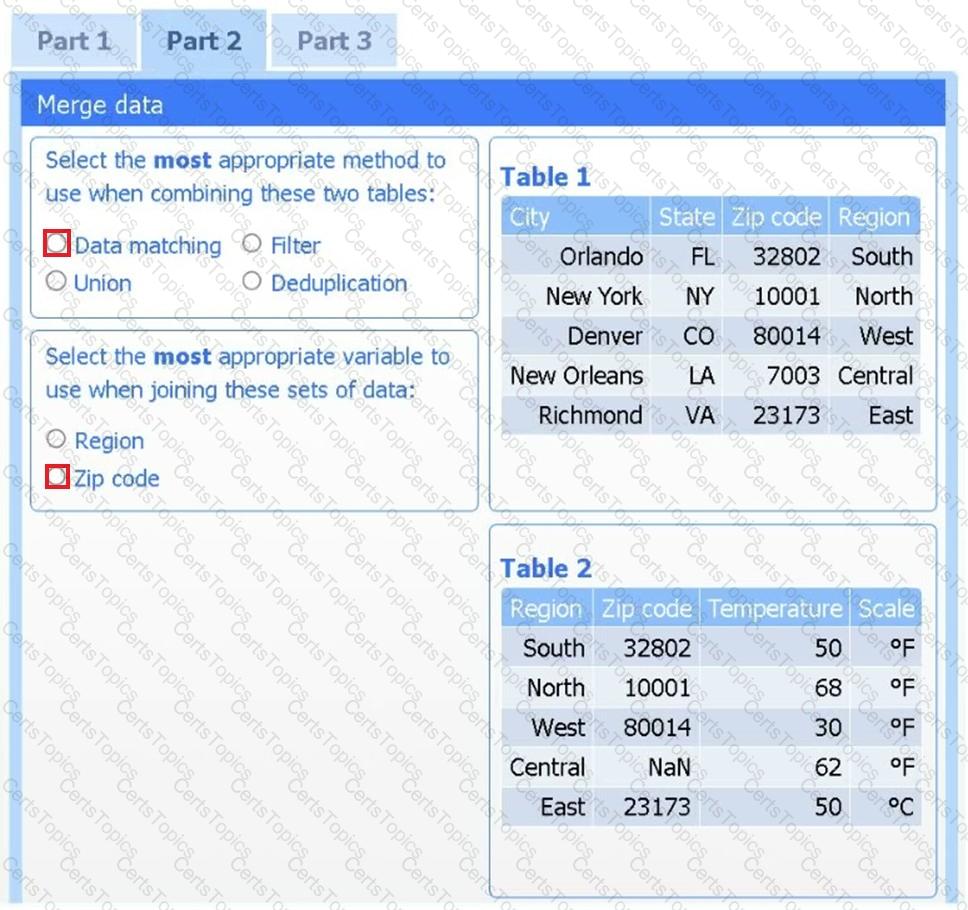
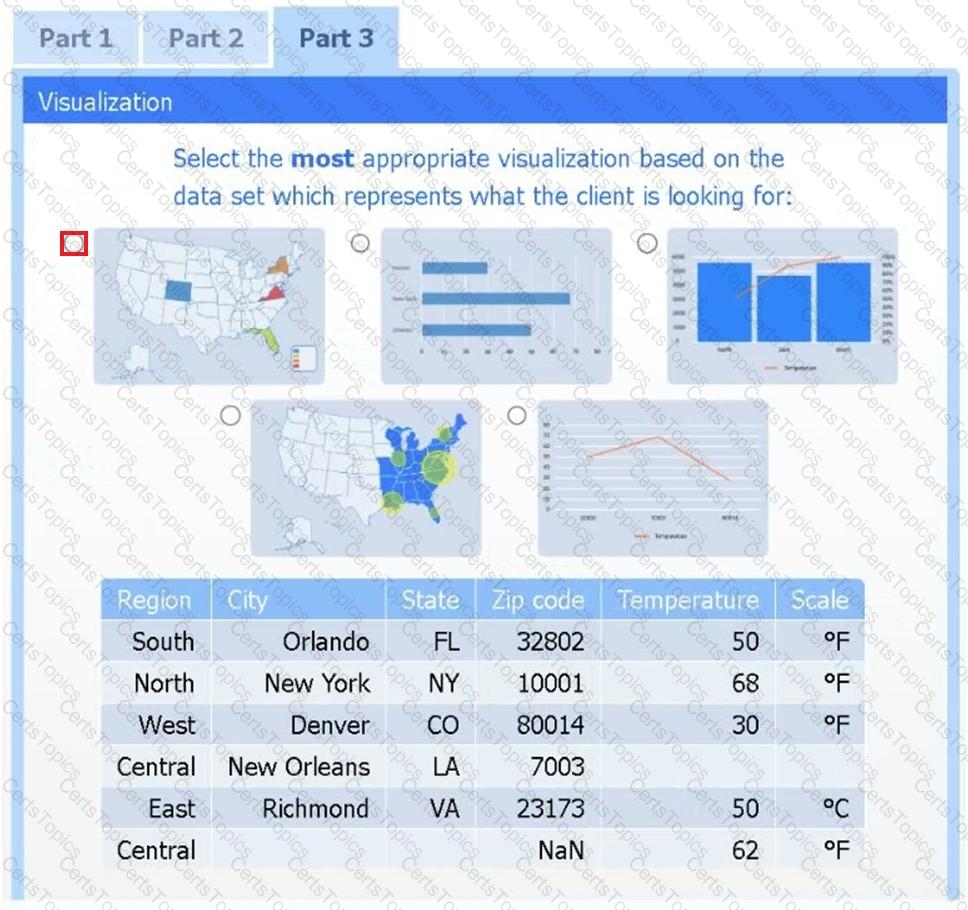
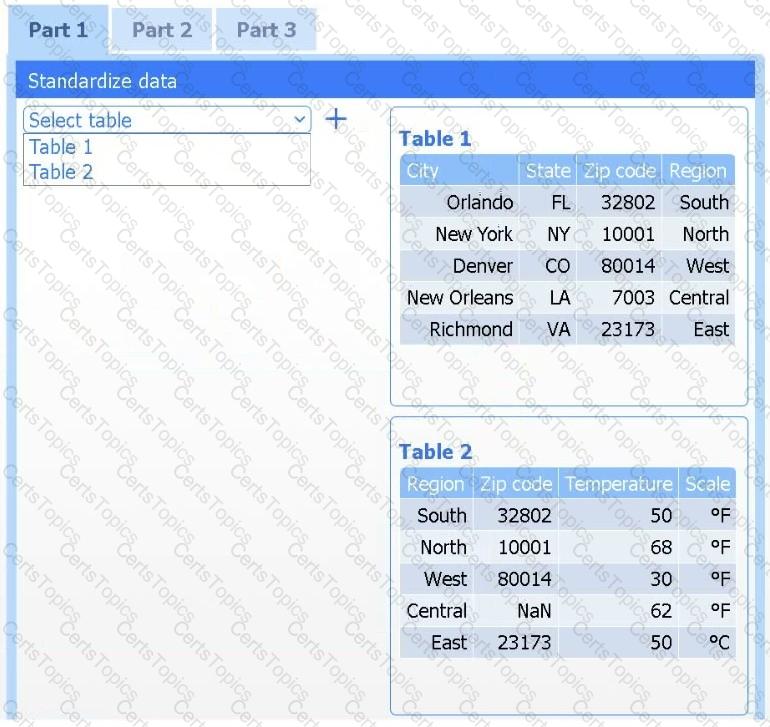
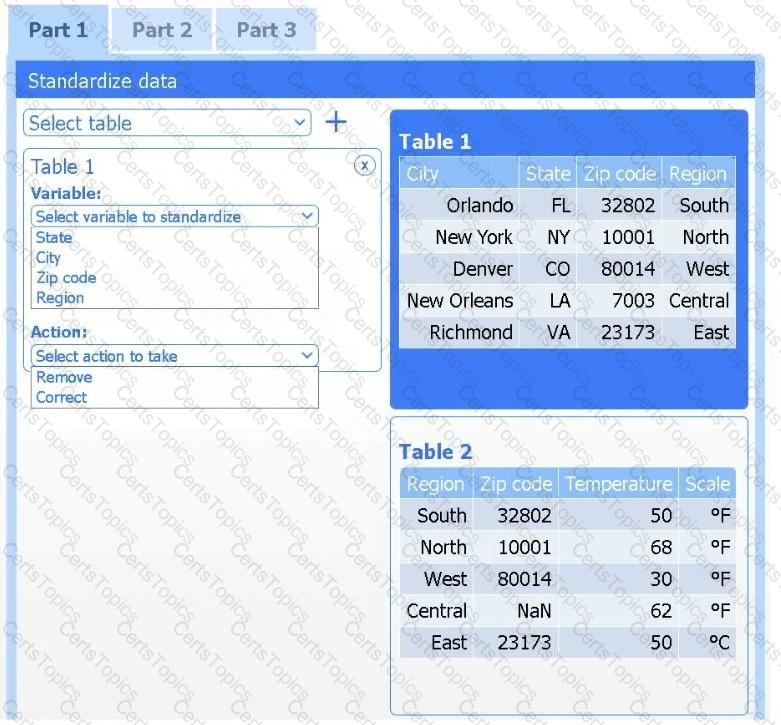
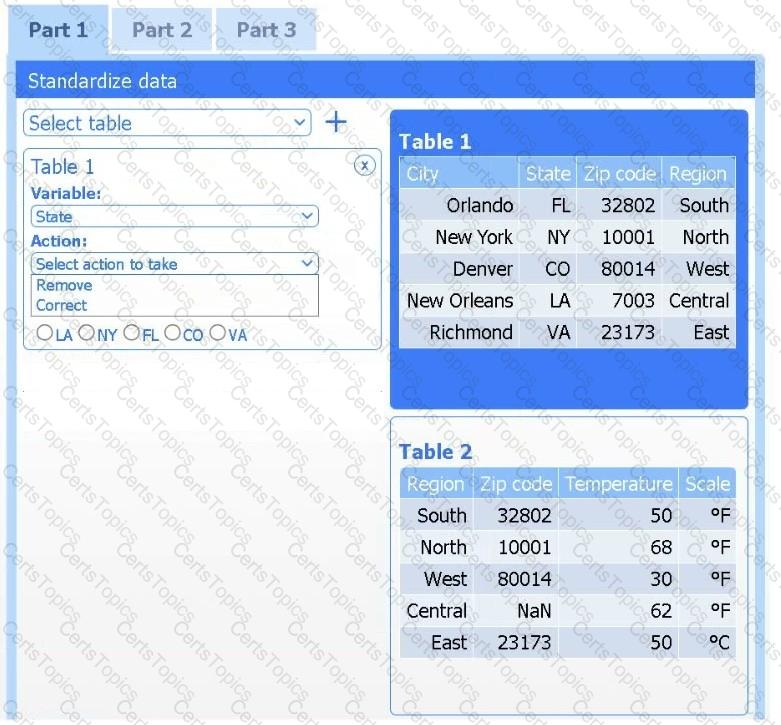
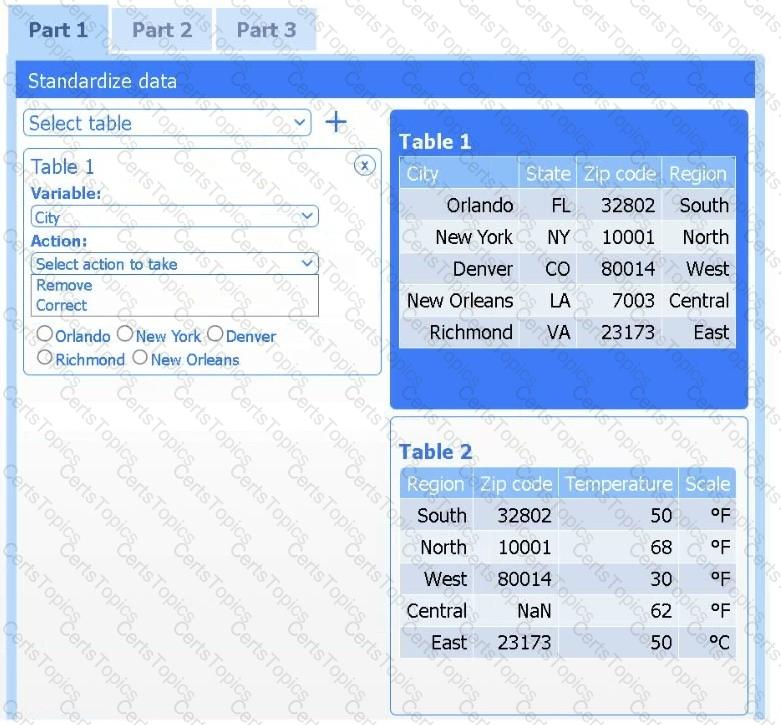
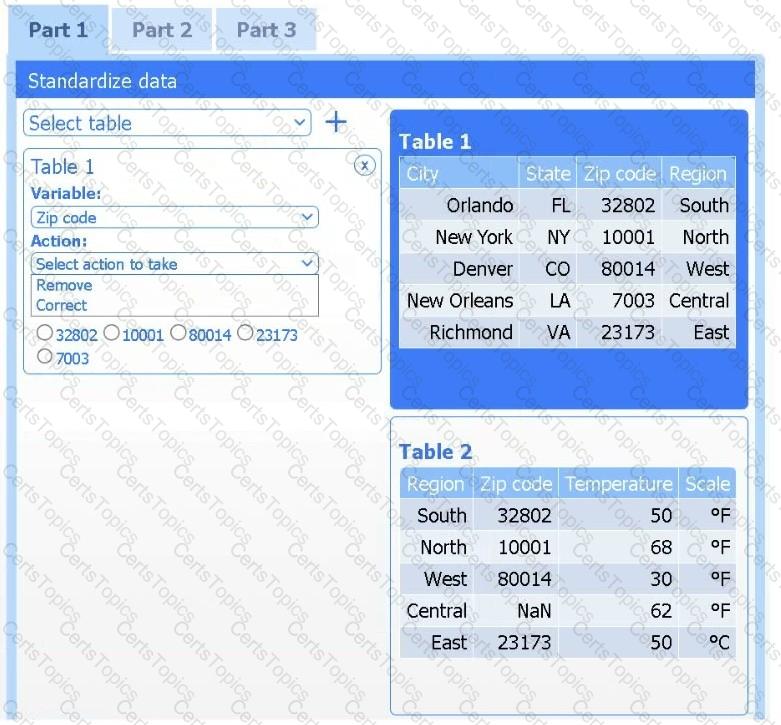
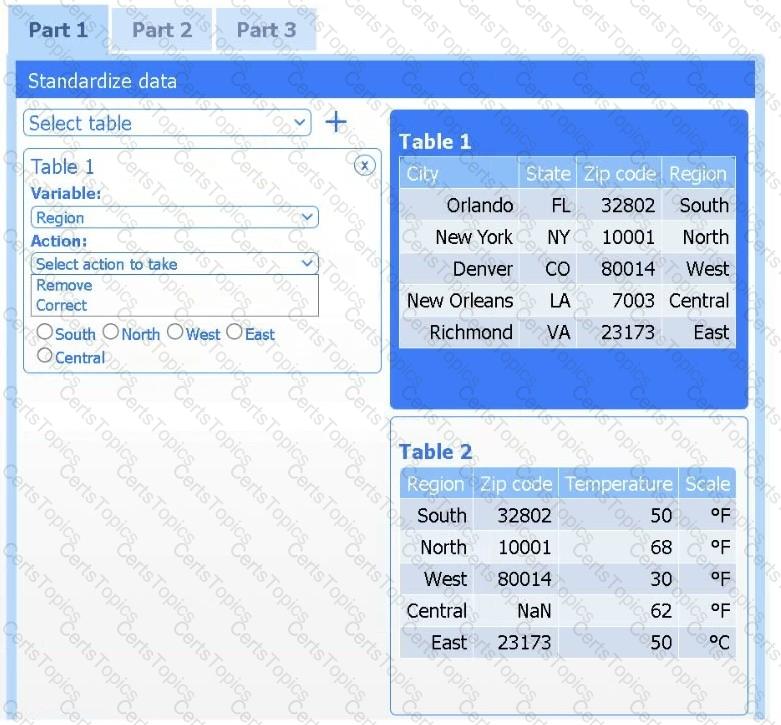
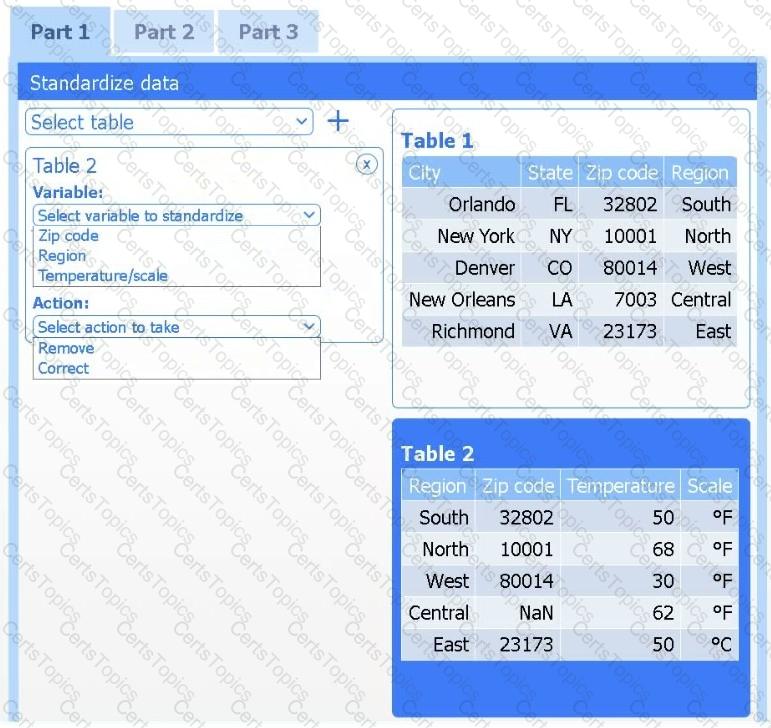
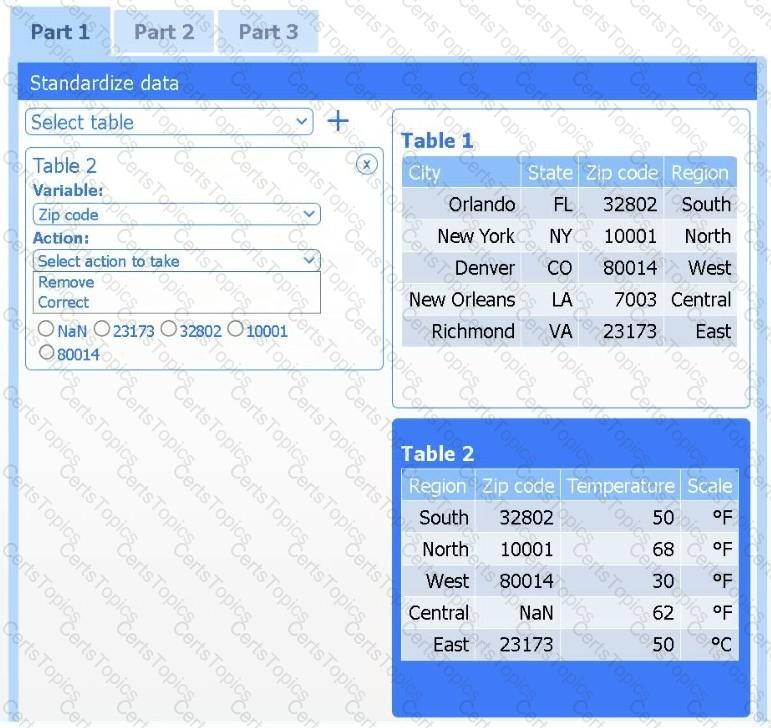
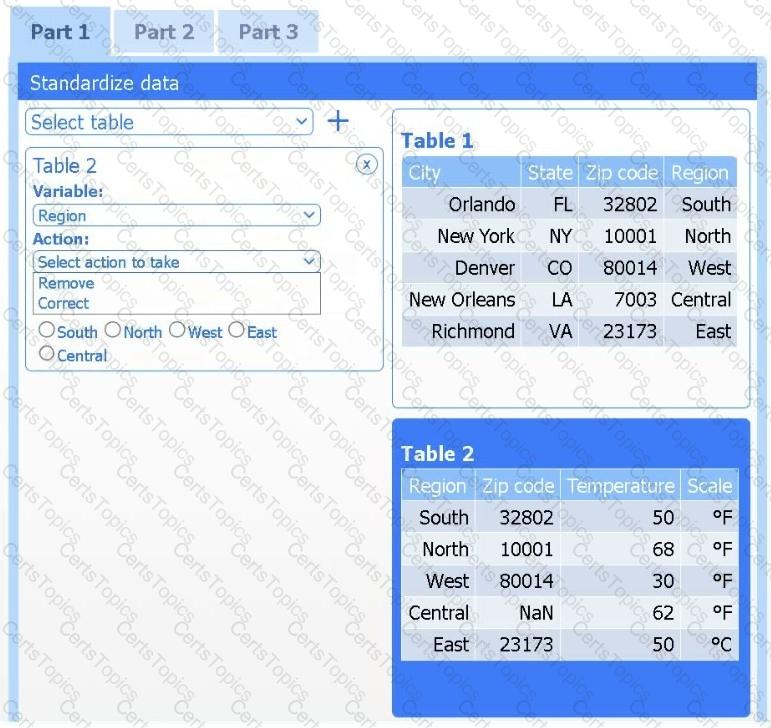
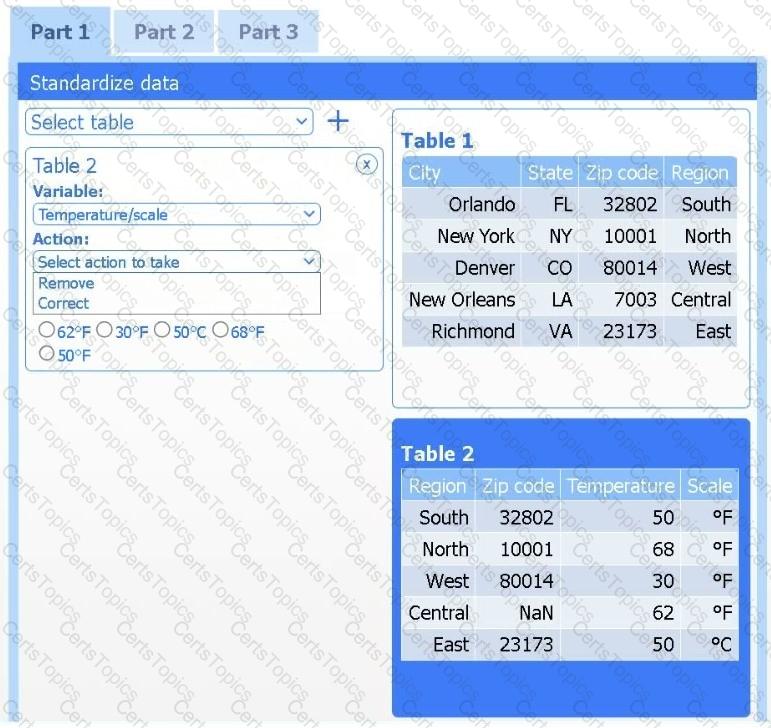
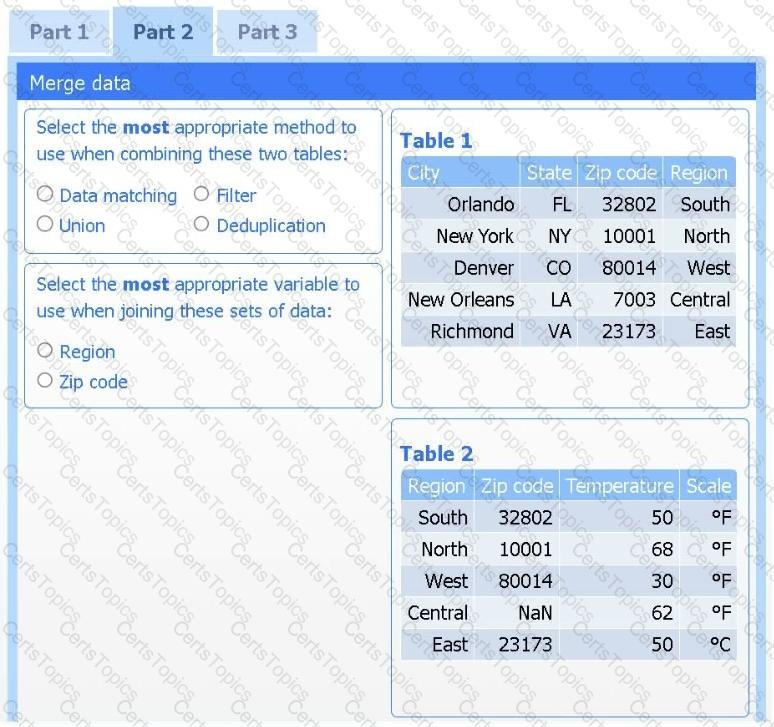
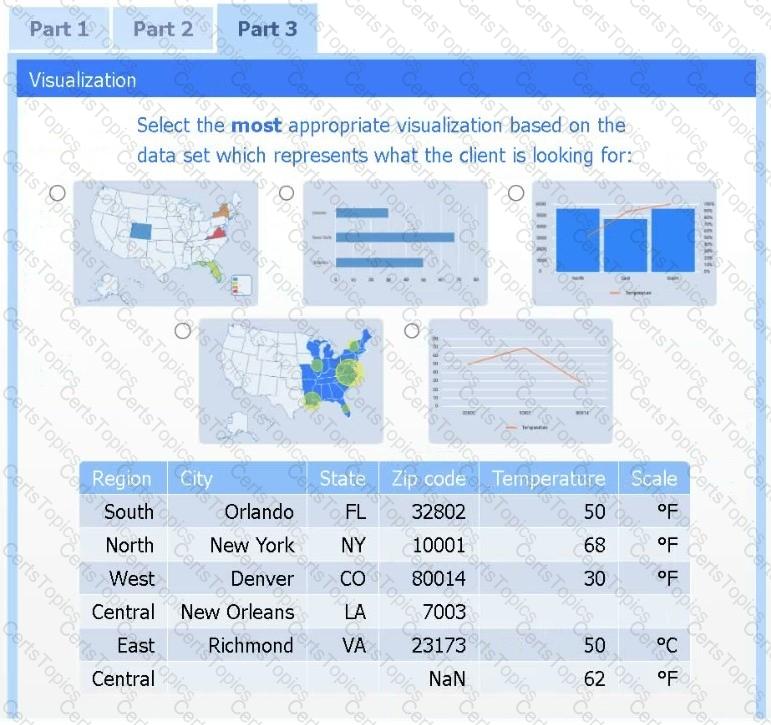
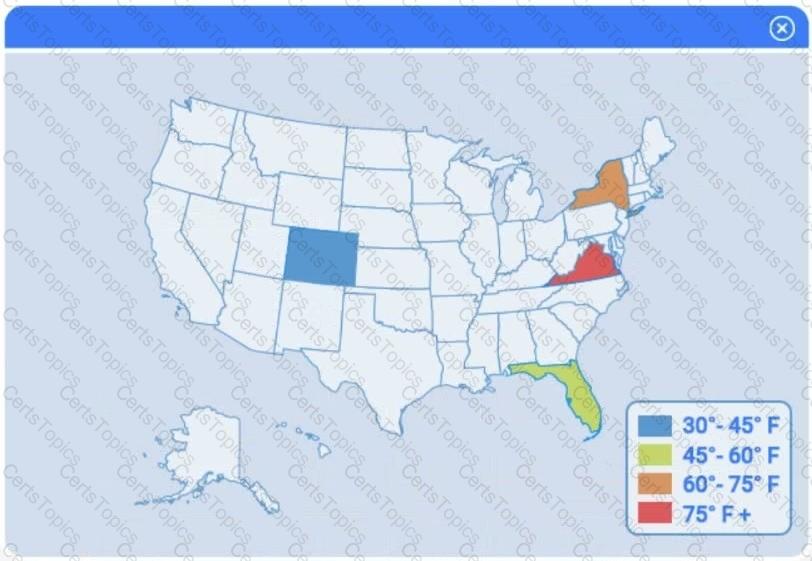
A client has gathered weather data on which regions have high temperatures. The client would like a visualization to gain a better understanding of the data.
INSTRUCTIONS
Part 1
Review the charts provided and use the drop-down menu to select the most appropriate way to standardize the data.
Part 2
Answer the questions to determine how to create one data set.
Part 3
Select the most appropriate visualization based on the data set that represents what the client is looking for.
If at any time you would like to bring back the initial state of the simulation, please click the Reset All button.
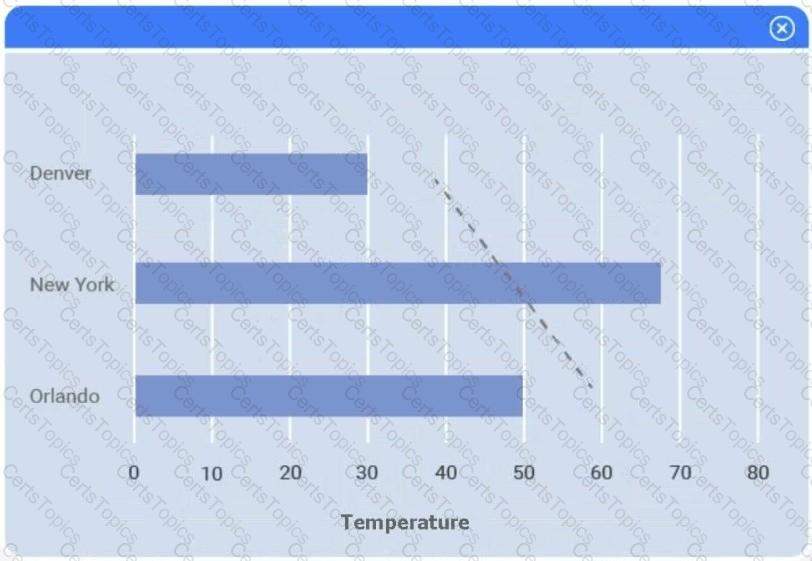
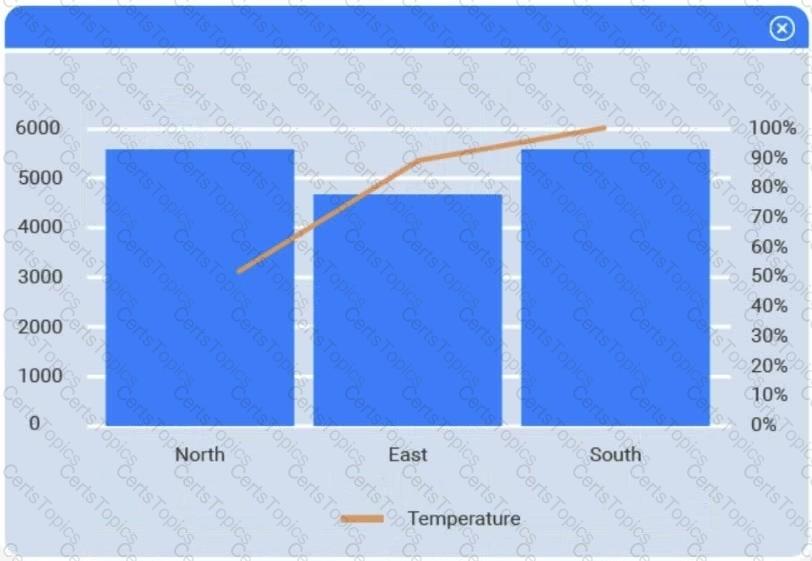
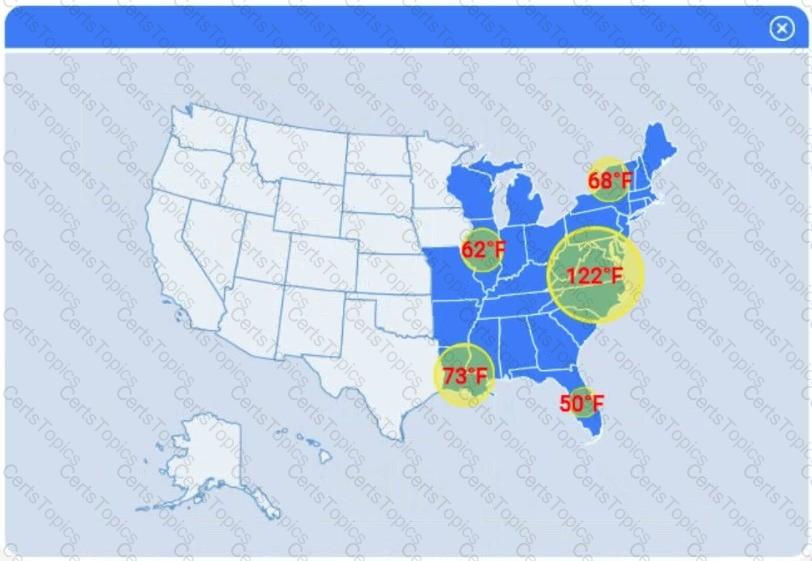
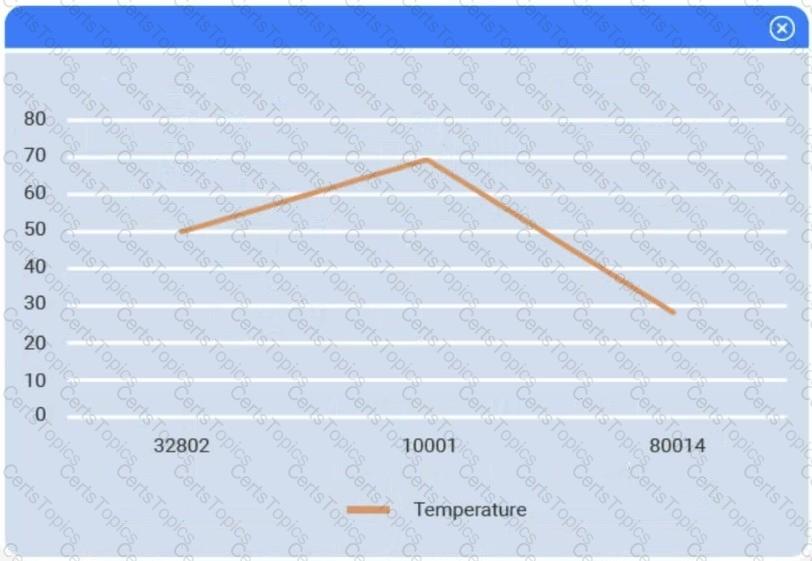
The following graphic shows the results of an unsupervised, machine-learning clustering model:
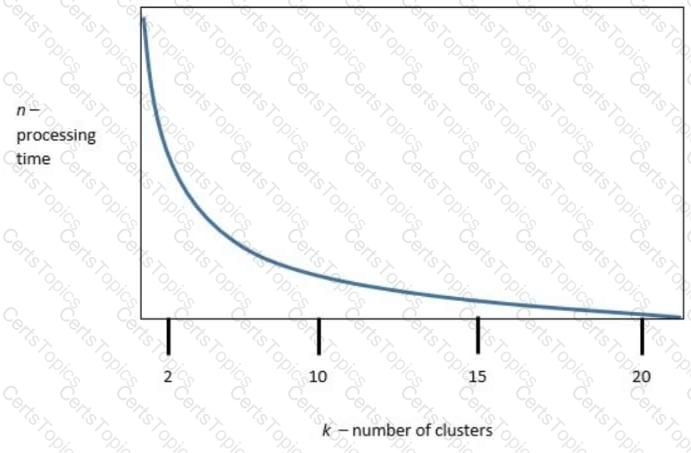
k is the number of clusters, and n is the processing time required to run the model. Which of the following is the best value of k to optimize both accuracy and processing requirements?
A data scientist is designing a real-time machine-learning model that classifies a user based on initial behavior. The run times of these models are provided in the following table:

Which of the following models should the data scientist recommend for deployment?
A statistician notices gaps in data associated with age-related illnesses and wants to further aggregate these observations. Which of the following is the best technique to achieve this goal?
Which of the following does k represent in the k-means model?
A data scientist receives an update on a business case about a machine that has thousands of error codes. The data scientist creates the following summary statistics profile while reviewing the logs for each machine:
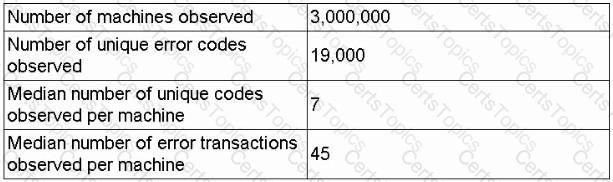
| Number of machines observed | 3,000,000
| Number of unique error codes observed | 19,000
| Median number of unique codes per machine | 7
| Median number of error transactions | 45
Which of the following is the most likely concern with respect to data design for model ingestion?
A data analyst is examining the correlation matrix of a new data set to identify issues that could adversely impact model performance. Which of the following is the analyst most likely checking for?
A data scientist is using the following confusion matrix to assess model performance:
Actually Fails
Actually Succeeds
Predicted to Fail
80%
20%
Predicted to Succeed
15%
85%

The model is predicting whether a delivery truck will be able to make 200 scheduled delivery stops.
Every time the model is correct, the company saves 1 hour in planning and scheduling.
Every time the model is wrong, the company loses 4 hours of delivery time.
Which of the following is the net model impact for the company?
A data scientist is working with a data set that covers a two-year period for a large number of machines. The data set contains:
Machine system ID numbers
Sensor measurement values
Daily timestamps for each machine
The data scientist needs to plot the total measurements from all the machines over the entire time period. Which of the following is the best way to present this data?
Which of the following distance metrics for KNN is best described as a straight line?
A data analyst wants to find the latitude and longitude of a mailing address. Which of the following is the best method to use?
Which of the following types of machine learning is a GPU most commonly used for?
A data scientist is standardizing a large data set that contains website addresses. A specific string inside some of the web addresses needs to be extracted. Which of the following is the best method for extracting the desired string from the text data?
A data analyst wants to save a newly analyzed data set to a local storage option. The data set must meet the following requirements:
Be minimal in size
Have the ability to be ingested quickly
Have the associated schema, including data types, stored with it
Which of the following file types is the best to use?
A data scientist is preparing to brief a non-technical audience that is focused on analysis and results. During the modeling process, the data scientist produced the following artifacts:
Which of the following artifacts should the data scientist include in the briefing? (Choose two.)
Which of the following belong in a presentation to the senior management team and/or C-suite executives? (Choose two.)
Which of the following environmental changes is most likely to resolve a memory constraint error when running a complex model using distributed computing?
Which of the following types of layers is used to downsample feature detection when using a convolutional neural network?
A data scientist wants to digitize historical hard copies of documents. Which of the following is the best method for this task?
Which of the following modeling tools is appropriate for solving a scheduling problem?
Given the equation:
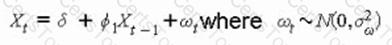
Xt = δ + ϕ1Xt−1 + ωt, where ωt ∼ N(0, σω²)
Which of the following time series models best represents this process?
Which of the following JOINS would generate the largest amount of data?
A movie production company would like to find the actors appearing in its top movies using data from the tables below. The resulting data must show all movies in Table 1, enriched with actors listed in Table 2.
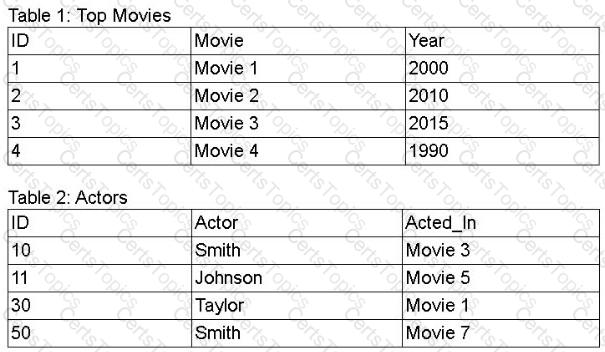
Which of the following query operations achieves the desired data set?
Copyright © 2021-2026 CertsTopics. All Rights Reserved