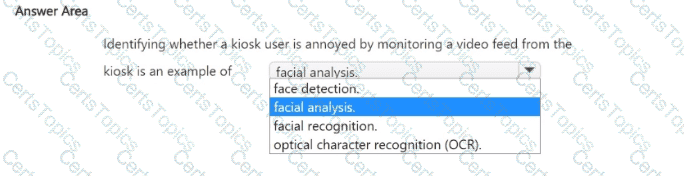
This question refers to a system that monitors a user’s emotions or expressions—in this case, identifying whether a kiosk user is annoyed—through a video feed. According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Identify Azure services for computer vision,” this scenario falls under facial analysis, which is a capability of Azure AI Vision or the Face API.
Facial analysis involves detecting human faces in images or video and analyzing facial features to interpret emotions, expressions, age, gender, or facial landmarks. The AI model does not try to identify who the person is but rather interprets how they appear or feel. For example, facial analysis can detect emotions such as happiness, anger, sadness, or surprise, which allows applications to infer a user’s engagement or frustration level while interacting with a system.
Option review:
Face detection: Identifies the presence and location of a face in an image but does not interpret expressions or emotions.
Facial recognition: Matches a detected face to a known individual’s identity (for authentication or security), not for emotion detection.
Optical character recognition (OCR): Extracts text from images or scanned documents and has no relation to human emotion or facial features.
Therefore, determining whether a kiosk user is annoyed, happy, or frustrated involves emotion detection within facial analysis, making Facial analysis the correct answer.
This aligns with AI-900’s definition of computer vision workloads, where facial analysis provides insights into emotions and expressions, supporting user experience optimization and customer behavior analytics.