Consider the following two relations, A and B.
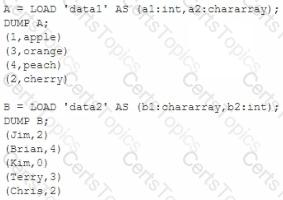
Which Pig statement combines A by its first field and B by its second field?
Review the following data and Pig code:
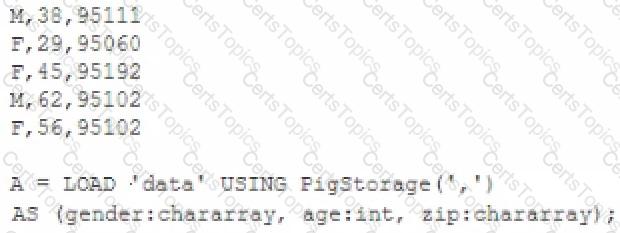
What command to define B would produce the output (M,62,95l02) when invoking the DUMP operator on B?
You have just executed a MapReduce job. Where is intermediate data written to after being emitted from the Mapper’s map method?
A NameNode in Hadoop 2.2 manages ______________.
Can you use MapReduce to perform a relational join on two large tables sharing a key? Assume that the two tables are formatted as comma-separated files in HDFS.
MapReduce v2 (MRv2/YARN) splits which major functions of the JobTracker into separate daemons? Select two.
What is the disadvantage of using multiple reducers with the default HashPartitioner and distributing your workload across you cluster?
Workflows expressed in Oozie can contain:
Which one of the following files is required in every Oozie Workflow application?
What types of algorithms are difficult to express in MapReduce v1 (MRv1)?
When can a reduce class also serve as a combiner without affecting the output of a MapReduce program?
Which one of the following statements is FALSE regarding the communication between DataNodes and a federation of NameNodes in Hadoop 2.2?
Which project gives you a distributed, Scalable, data store that allows you random, realtime read/write access to hundreds of terabytes of data?
To process input key-value pairs, your mapper needs to lead a 512 MB data file in memory. What is the best way to accomplish this?
For each intermediate key, each reducer task can emit:
Which of the following tool was designed to import data from a relational database into HDFS?
Copyright © 2021-2025 CertsTopics. All Rights Reserved
