MapReduce v2 (MRv2/YARN) is designed to address which two issues?
Which one of the following statements describes the relationship between the ResourceManager and the ApplicationMaster?
Which Hadoop component is responsible for managing the distributed file system metadata?
You have user profile records in your OLPT database, that you want to join with web logs you have already ingested into the Hadoop file system. How will you obtain these user records?
In Hadoop 2.0, which TWO of the following processes work together to provide automatic failover of the NameNode? Choose 2 answers
All keys used for intermediate output from mappers must:
You have just executed a MapReduce job. Where is intermediate data written to after being emitted from the Mapper’s map method?
You have the following key-value pairs as output from your Map task:
(the, 1)
(fox, 1)
(faster, 1)
(than, 1)
(the, 1)
(dog, 1)
How many keys will be passed to the Reducer’s reduce method?
Which one of the following statements is FALSE regarding the communication between DataNodes and a federation of NameNodes in Hadoop 2.0?
Given the following Hive command:
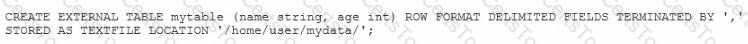
Which one of the following statements is true?
Given the following Hive commands:

Which one of the following statements Is true?
Which one of the following statements regarding the components of YARN is FALSE?
Your client application submits a MapReduce job to your Hadoop cluster. Identify the Hadoop daemon on which the Hadoop framework will look for an available slot schedule a MapReduce operation.
Review the following data and Pig code.
M,38,95111
F,29,95060
F,45,95192
M,62,95102
F,56,95102
A = LOAD 'data' USING PigStorage('.') as (gender:Chararray, age:int, zlp:chararray);
B = FOREACH A GENERATE age;
Which one of the following commands would save the results of B to a folder in hdfs named myoutput?
In a MapReduce job, the reducer receives all values associated with same key. Which statement best describes the ordering of these values?
Copyright © 2021-2025 CertsTopics. All Rights Reserved
