(You are experiencing low throughput from a Java producer.
Kafka producer metrics show a low I/O thread ratio and low I/O thread wait ratio.
What is the most likely cause of the slow producer performance?)
A stream processing application is consuming from a topic with five partitions. You run three instances of the application. Each instance has num.stream.threads=5.
You need to identify the number of stream tasks that will be created and how many will actively consume messages from the input topic.
Which two statements are correct about transactions in Kafka?
(Select two.)
You have a topic t1 with six partitions. You use Kafka Connect to send data from topic t1 in your Kafka cluster to Amazon S3. Kafka Connect is configured for two tasks.
How many partitions will each task process?
(You started a new Kafka Connect worker.
Which configuration identifies the Kafka Connect cluster that your worker will join?)
What is a consequence of increasing the number of partitions in an existing Kafka topic?
What is the default maximum size of a message the Apache Kafka broker can accept?
Your application is consuming from a topic configured with a deserializer.
It needs to be resilient to badly formatted records ("poison pills"). You surround the poll() call with a try/catch for RecordDeserializationException.
You need to log the bad record, skip it, and continue processing.
Which action should you take in the catch block?
(You have a Kafka Connect cluster with multiple connectors deployed.
One connector is not working as expected.
You need to find logs related to that specific connector to investigate the issue.
How can you find the connector’s logs?)
Which two producer exceptions are examples of the class RetriableException? (Select two.)
Which configuration allows more time for the consumer poll to process records?
(You need to send a JSON message on the wire. The message key is a string.
How would you do this?)
Your application is consuming from a topic with one consumer group.
The number of running consumers is equal to the number of partitions.
Application logs show that some consumers are leaving the consumer group during peak time, triggering a rebalance. You also notice that your application is processing many duplicates.
You need to stop consumers from leaving the consumer group.
What should you do?
You are experiencing low throughput from a Java producer.
Metrics show low I/O thread ratio and low I/O thread wait ratio.
What is the most likely cause of the slow producer performance?
The producer code below features a Callback class with a method called onCompletion().
When will the onCompletion() method be invoked?
You need to explain the best reason to implement the consumer callback interface ConsumerRebalanceListener prior to a Consumer Group Rebalance.
Which statement is correct?
(Which configuration is valid for deploying a JDBC Source Connector to read all rows from the orders table and write them to the dbl-orders topic?)
Which two statements are correct when assigning partitions to the consumers in a consumer group using the assign() API?
(Select two.)
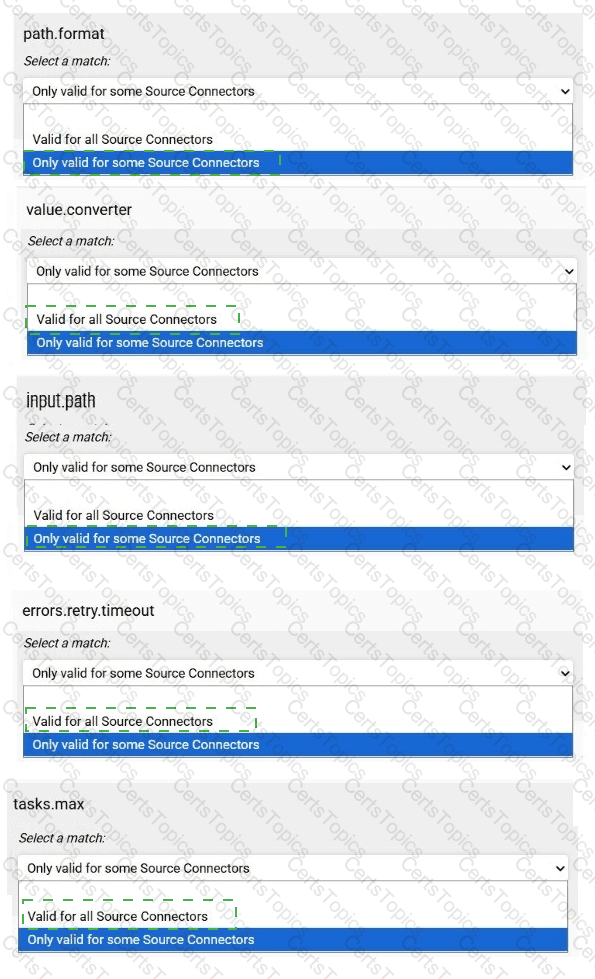
Match each configuration parameter with the correct option.
To answer choose a match for each option from the drop-down. Partial
credit is given for each correct answer.
(You are building real-time streaming applications using Kafka Streams.
Your application has a custom transformation.
You need to define custom processors in Kafka Streams.
Which tool should you use?)
The producer code below features a Callback class with a method called onCompletion().
In the onCompletion() method, when the request is completed successfully, what does the value metadata.offset() represent?
You need to correctly join data from two Kafka topics.
Which two scenarios will allow for co-partitioning?
(Select two.)
You need to configure a sink connector to write records that fail into a dead letter queue topic. Requirements:
Topic name: DLQ-Topic
Headers containing error context must be added to the messagesWhich three configuration parameters are necessary?(Select three.)
(You are configuring a source connector that writes records to an Orders topic.
You need to send some of the records to a different topic.
Which Single Message Transform (SMT) is best suited for this requirement?)
You are working on a Kafka cluster with three nodes. You create a topic named orders with:
replication.factor = 3
min.insync.replicas = 2
acks = allWhat exception will be generated if two brokers are down due to network delay?
A stream processing application is tracking user activity in online shopping carts.
You want to identify periods of user inactivity.
Which type of Kafka Streams window should you use?
You need to collect logs from a host and write them to a Kafka topic named 'logs-topic'. You decide to use Kafka Connect File Source connector for this task.
What is the preferred deployment mode for this connector?
Copyright © 2021-2026 CertsTopics. All Rights Reserved