An MLOps engineer is building a Pandas UDF that applies a language model that translates English strings into Spanish. The initial code is loading the model on every call to the UDF, which is hurting the performance of the data pipeline.
The initial code is:

def in_spanish_inner(df: pd.Series) -> pd.Series:
model = get_translation_model(target_lang='es')
return df.apply(model)
in_spanish = sf.pandas_udf(in_spanish_inner, StringType())
How can the MLOps engineer change this code to reduce how many times the language model is loaded?
A data engineer is working on the DataFrame:
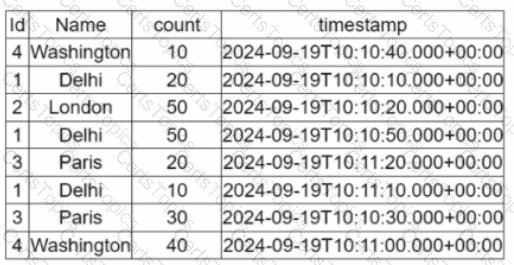
(Referring to the table image: it has columns Id, Name, count, and timestamp.)
Which code fragment should the engineer use to extract the unique values in the Name column into an alphabetically ordered list?
49 of 55.
In the code block below, aggDF contains aggregations on a streaming DataFrame:
aggDF.writeStream \
.format("console") \
.outputMode("???") \
.start()
Which output mode at line 3 ensures that the entire result table is written to the console during each trigger execution?
41 of 55.
A data engineer is working on the DataFrame df1 and wants the Name with the highest count to appear first (descending order by count), followed by the next highest, and so on.
The DataFrame has columns:
id | Name | count | timestamp
---------------------------------
1 | USA | 10
2 | India | 20
3 | England | 50
4 | India | 50
5 | France | 20
6 | India | 10
7 | USA | 30
8 | USA | 40
Which code fragment should the engineer use to sort the data in the Name and count columns?
Copyright © 2021-2026 CertsTopics. All Rights Reserved
