Which statement describes integration testing?
Which statement describes the correct use of pyspark.sql.functions.broadcast?
A data engineer wants to join a stream of advertisement impressions (when an ad was shown) with another stream of user clicks on advertisements to correlate when impression led to monitizable clicks.

Which solution would improve the performance?
A)
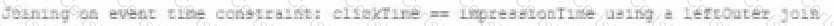
B)
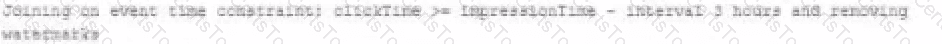
C)
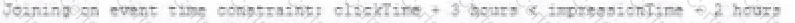
D)

Which distribution does Databricks support for installing custom Python code packages?
Copyright © 2021-2026 CertsTopics. All Rights Reserved
