Which native Nutanix tool is used to determine connectivity between two sites during disaster recovery testing?
Two AHV clusters are 4 ms RTT apart. The business requires:
0 RPO
Automatic failover
No application performance degradation
Hybrid HCI nodes with 100 TB capacity
What storage configuration must be validated before enabling synchronous replication?
Which file system is supported on Linux VMs for Self-Service Restore?
An administrator configures a protection policy that replicates workloads to two different recovery AZs (multisite deployment). Replication to both recovery AZs is successful. However, when attempting to perform failover to the second recovery AZ, the administrator cannot select it as a failover target.
Which setup step was most likely missed?
A remote office deployment consists of a two-node Nutanix hybrid cluster. An administrator attempts to configure a protection domain with a 5-minute RPO (Nearsync) replicating to a central datacenter.
Why is the administrator unable to successfully configure this Nearsync schedule?
An administrator notices that storage utilization continues to increase at both the primary and recovery sites after implementing a third-party backup solution that uses protection policies. Which configuration should be reviewed first?
An administrator is tasked with ensuring the VMs do not experience downtime during an upcoming network maintenance on the primary cluster. The VMs are protected by a Protection Policy and are configured under a Recovery Plan. What failover mechanism should the administrator use to ensure the VMs are available on the target cluster before the maintenance window?
An administrator is migrating from a Protection Domain-based deployment to a Prism Central (PC)-based deployment. What occurs if a snapshot is deleted before the protection policy is applied to the migrated entities?
An administrator notices that VM replication from ClusterA to ClusterB fails consistently at the same point during the replication job. The following observations are noted by the administrator:
The Prism dashboard shows the replication job failing during snapshot creation.
ClusterB storage pool and container usage is under 80%, well below capacity.
Network latency/Pings between ClusterA and ClusterB averages 3ms, with occasional spikes to 25ms.
VM event logs indicate frequent I/O timeout errors during the replication window.
Both clusters are running compatible AOS versions.
What is the most likely cause for the failing replications?
Which two Data Protection technologies are compatible with Self-Service Restore? (Choose two.)
A security team has detected a ransomware attack that began encrypting files on the primary site at 2:00 AM. By 2:45 AM, the primary site is still accessible but workloads are compromised. The administrator needs to recover to a known-good state from before the attack.
Which statement shows the action and reasoning that the administrator should consider?
An administrator executes a Recovery Plan for a set of high-performance VMs configured with SR-IOV network adapters. The VMs failover successfully to the Recovery Cluster.
What is the state of these VMs immediately after the planned failover completes?
Which statement describes the most efficient and least disruptive method to achieve a file-level recovery without rolling back the entire VM?
An administrator is testing the failover scenarios from a source availability zone (AZ1) to a destination availability zone (AZ2). The administrator successfully performs an unplanned failover from AZ1 to AZ2. The administrator then immediately tries to use the unplanned failover option to fail the VM back to AZ1, but does not see the VM listed under Recovery Plan. What could be the cause?
An administrator is managing a mission-critical Inventory-VM that is part of a Protection Domain (PD) named PD_Production.
Monday: A scheduled snapshot of PD_Production is successfully taken.
Tuesday: Due to a configuration error during a cleanup task, the administrator accidentally removes Inventory-VM from the PD_Production Protection Domain. The VM continues to run, but it is no longer being snapped or replicated.
Wednesday: A database corruption occurs on Inventory-VM. The administrator finds the local snapshot from Monday and performs an In-place Restore (Revert) to recover the data.
Following the successful completion of the In-place Restore, what is the status of Inventory-VM regarding its data protection?
An administrator wants to run a test failover and maps the primary production virtual network to the recovery site production virtual network for the test. What are the two most likely outcomes? (Choose two.)
An administrator enables network segmentation for Disaster Recovery on a primary cluster to isolate replication traffic. The primary and recovery clusters are in a " brownfield " configuration, meaning the recovery cluster does not yet have network segmentation enabled.
How is the configuration of the recovery cluster handled in this scenario?
A sudden and unrecoverable hardware failure occurs at the primary site, making the Prism Element console for that cluster inaccessible. The secondary site is healthy and contains the latest replicated snapshots. Which action must the administrator take on the secondary cluster to restore the VMs?
Which combination of Replication Schedules within the same Recovery Plan will cause the recovery to fail?
An administrator configures a VM-VM Anti-Affinity policy for a web application cluster to ensure high availability. The application is protected by a Protection Policy in Prism Central. A failover occurs, moving the VMs to the recovery site.
What determines whether the VM-VM Anti-Affinity rules are active on the recovery site?
A company is recovering a 3-tier application (Database, Middleware, Web). The administrator executes the Recovery Plan. The Web tier VMs start up but applications immediately crash because they cannot connect to the Database tier. Which setting in the Recovery Plan should the administrator have configured to prevent this execution failure?
An administrator wants to protect the snapshots created on the cluster. Only authorized users should be allowed to modify or delete the snapshots on the cluster. How can the administrator harden the security of the snapshots?
An organization uses a Recovery Plan to protect a SQL Cluster that relies on Volume Groups (VGs). The VGs are configured with hypervisor attachments. The administrator executes a Planned Failover to migrate the SQL Cluster to the Recovery Site. The Failover task completes successfully, but the database administrators report that the database is offline. What is the possible cause of this issue?
A Protection Policy is configured with a Nearsync replication schedule (15-minute RPO). An administrator observes that the system has temporarily transitioned to an hourly replication schedule. Which scenario would cause this automatic transition from Nearsync to Asynchronous (hourly) replication?
Exhibit:
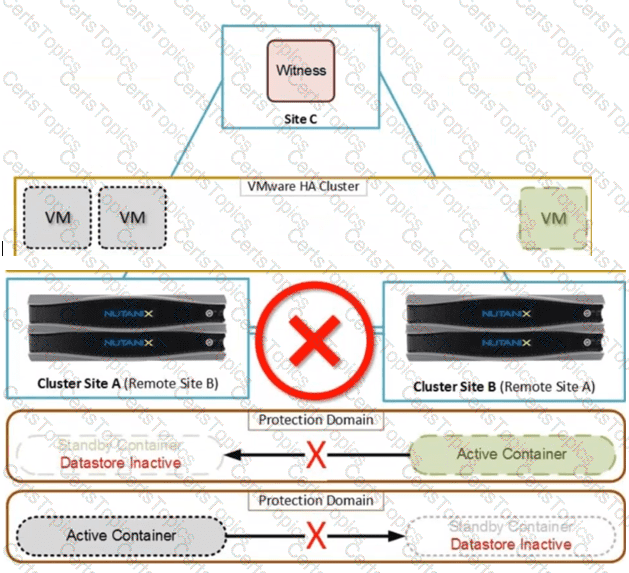
An administrator wants to protect the snapshots created on the cluster. Only authorized users should be allowed to modify or delete the snapshots on the cluster. How can the administrator harden the security of the snapshots?
Which ports must remain open to support replication between two Prism Element clusters?
An administrator has recently completed the initial configuration of Nutanix Disaster Recovery for a production environment. Protection Policies and Recovery Plans have been configured and validated by the senior infrastructure team.
The administrator has confirmed that the expected categories are correctly associated with both the Protection Policies and Recovery Plans. During a scheduled test failover, the administrator notices that several VMs are missing from the recovery.
The administrator reviews the environment and notes the following:
The Protection Summary tab does not show any warnings or errors
No replication tasks are currently ongoing
The missing VMs were all deployed within the last two weeks as part of a new application rollout
The missing VMs are running on the same cluster as other VMs that recovered successfully during the test failover
The application team followed the standard VM deployment checklist but did not coordinate with the infrastructure team during provisioning
Given this information, what is the most likely cause of the missing VMs?
An administrator needs to provide leadership with a report showing the timeframe of each step during Recovery Plan failover testing. How should the administrator produce this report?
A deployment uses native encryption for replication traffic between two clusters. An administrator subsequently enables network segmentation to isolate this traffic. Which specific maintenance step must be performed to ensure the encrypted replication functions correctly on the new segmented network?
An administrator plans on performing a failover of a VM from a source cluster to a DR cluster. The administrator needs the VM ' s IP address preserved after failover. In what scenario is the VM ' s IP address preserved?
A financial institution is designing a disaster recovery solution for a business-critical application that requires a zero recovery point objective (RPO). The infrastructure team decides to implement Nutanix Metro Availability between two physical data centers (DC-Alpha and DC-Beta) interconnected by a dedicated dark fiber. What is the maximum possible network latency on this link for this configuration to function correctly?
The Disaster Recovery dashboard in Prism Central shows that the protection domain is out of sync and new recovery points are no longer being created at the recovery site. No recent changes were made to the protection policy configuration or RPO settings. During initial troubleshooting, an administrator has observed the following:
Production VMs are running normally at the primary site.
The recovery cluster is reachable from Prism Central.
No storage capacity alerts are seen on either cluster.
A recent network change was implemented to enable network segmentation between clusters.
New firewall rules were introduced recently as part of a security hardening effort.
Which action should the administrator take first when evaluating this issue?
Copyright © 2021-2026 CertsTopics. All Rights Reserved
