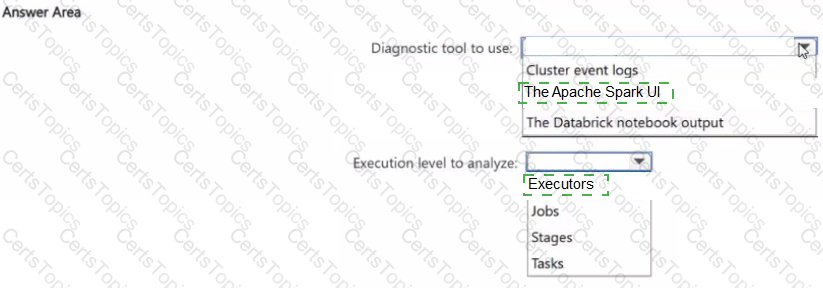
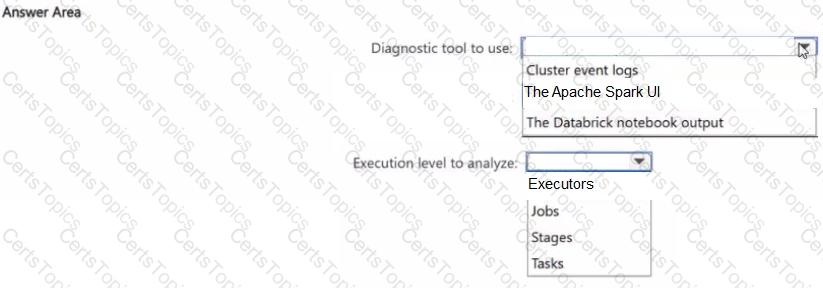
You have an Azure Databricks workspace that contains an all-purpose cluster named Cluster1.
You discover that out of- memory (OOM) errors intermittently cause jobs running on Cluster1 to fail.
You need to identify the root cause of the failures by analyzing the runtime execution behavior. What should you do? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You have an Azure Databricks workspace that is enabled for Unity Catalog and contains a Delta table named Sales_orders. Sales.orders stores historical sales data.
You receive a daily CSV file daily that contains new sales records only. The file does NOT contain updates to existing rows You need to load the daily data into Sales.orders. The solution must meet the following requirements:
• Preserve the existing data.
• Add only the new records.
• Minimize processing effort.
Which command should include in the loading strategy?
You have an Azure Databricks workspace that uses Unity Catalog.
You have a Lakeflow Spark Declarative Pipelines (SDP) pipeline that ingests data into a managed Delta table named Table1. Table! is used for analytics.
New columns are added to the source data, causing pipeline failures during writes to Table!
You need to prevent the pipeline failures. The solution must ensure that schema changes are detected and handled.
What should you do?
You have an Azure Databricks workspace that is enabled for Unity Catalog
You have a complex job named Job1 that contains eight tasks. Job! takes multiple hours to complete
During the last job run, the final task fails due to a transient issue.
You need to retry the last task without rerunning tasks that have already completed.
What should you do?
You need to deploy Databricks Asset Bundles to a development environment. The solution must support automated and repeatable deployments across environments.
What should you use?
You have an Azure Databticks workspace that contains an all-purpose compute cluster named Cluster1. Cluser1 is used for
interactive development.
You need to configure Cluster1 to meet the following requirements:
• Automatically add and remove worker nodes based on workload demand
• Automatically shut down when the cluster has been idle for a specific period.
What should you configure for each requirement? To answer, drag the appropriate options to the correct requirements. Each option may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content
NOTE: Each correct selection is worth one point.

You have an Azure Databricks workspace that is enabled for Unity Catalog and contains a Delta table named Orders.
You load the Orders table into an Apache Spark DataFrame named df.
You need to create a DataFrame that excludes rows where the order amount is null.
Solution: You run the following expression.
df.dropna(subset=["order_amount"])
Does this meet the goal?
You have an Azure Databricks workspace that is enabled for Unity Catalog and contains a Delta table named Orders.
You load the Orders table into an Apache Spark DataFrame named df.
You need to create a DataFrame that excludes rows where the order amount is null.
Solution: You run the following expression.
df.filter(df.order_amount != None)
Does this meet the goal?
You have an Azure Databricks workspace named Workspace1 that contains a lakehouse and is enabled for Unity Catalog.
You have a connection to a Microsoft SQL Server database named DB1.
You need to expose the schemas and tables of DB1 to meet the following requirements:
• The schemas and tables can be queried in Databricks.
• The schemas and tables appear alongside other Unity Catalog objects.
• The data is NOT copied into Databricks-managed storage.
Solution: You create a Databricks access connector.
Does this meet the goal?
You need to develop the task logic for a new job in Lakeflow Jobs that processes telemetry data.
Each task must contain only the appropriate logic for its step in the pipeline. The solution must support the planned changes and meet the data ingestion and processing requirements.
What should you do?
Which ingestion option should you recommend for each data source? To answer, drag the appropriate options to the correct data sources. Each option may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

Which SCD type should you use to support the planned data modeling changes? To answer, drag the appropriate types to the correct issues. Each type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

You need to configure compute for the ingestion of telemetry data. The solution must meet the data ingestion and processing requirements.
What should you do?
You need to complete the PySpark code for the Spark Structured Streaming pipelines. The solution must meet the data ingestion and processing requirements.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Copyright © 2021-2026 CertsTopics. All Rights Reserved