You are developing a prediction model. Your team indicates they need an algorithm that is fast and requires low memory and low processing power. Assuming the following algorithms have similar accuracy on your data, which is most likely to be an ideal choice for the job?
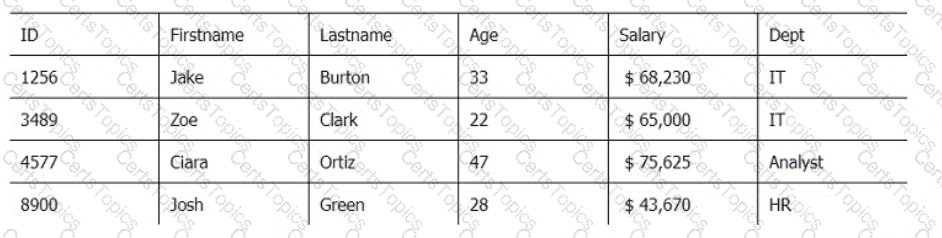
Below are three tables: Employees, Departments, and Directors.
Employee_Table
Department_Table
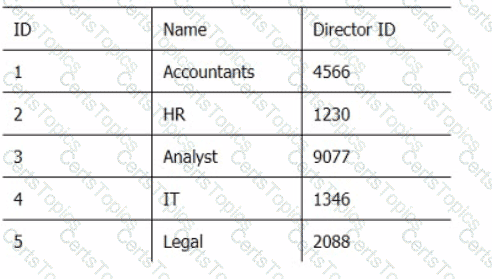
Director_Table
ID
Firstname
Lastname
Age
Salary
DeptJD
4566
Joey
Morin
62
$ 122,000
1
1230
Sam
Clarck
43
$ 95,670
2
9077
Lola
Russell
54
$ 165,700
3
1346
Lily
Cotton
46
$ 156,000
4
2088
Beckett
Good
52
$ 165,000
5
Which SQL query provides the Directors' Firstname, Lastname, the name of their departments, and the average employee's salary?
Which of the following statements are true regarding highly interpretable models? (Select two.)
Your dependent variable Y is a count, ranging from 0 to infinity. Because Y is approximately log-normally distributed, you decide to log-transform the data prior to performing a linear regression.
What should you do before log-transforming Y?
Which two of the following statements about the beta value in an A/B test are accurate? (Select two.)
When should you use semi-supervised learning? (Select two.)
Which type of regression represents the following formula: y = c + b*x, where y = estimated dependent variable score, c = constant, b = regression coefficient, and x = score on the independent variable?
Workflow design patterns for the machine learning pipelines:
Which of the following is NOT an activation function?
Which two encoders can be used to transform categorical data into numerical features? (Select two.)
Which of the following tests should be performed at the production level before deploying a newly retrained model?
Your dependent variable data is a proportion. The observed range of your data is 0.01 to 0.99. The instrument used to generate the dependent variable data is known to generate low quality data for values close to 0 and close to 1. A colleague suggests performing a logit-transformation on the data prior to performing a linear regression. Which of the following is a concern with this approach?
Definition of logit-transformation
If p is the proportion: logit(p)=log(p/(l-p))
A healthcare company experiences a cyberattack, where the hackers were able to reverse-engineer a dataset to break confidentiality.
Which of the following is TRUE regarding the dataset parameters?
Which two encodes can be used to transform categories data into numerical features? (Select two.)
A classifier has been implemented to predict whether or not someone has a specific type of disease. Considering that only 1% of the population in the dataset has this disease, which measures will work the BEST to evaluate this model?
We are using the k-nearest neighbors algorithm to classify the new data points. The features are on different scales.
Which method can help us to solve this problem?
An organization sells house security cameras and has asked their data scientists to implement a model to detect human feces, as distinguished from animals, so they can alert th customers only when a human gets close to their house.
Which of the following algorithms is an appropriate option with a correct reason?
Given a feature set with rows that contain missing continuous values, and assuming the data is normally distributed, what is the best way to fill in these missing features?
An HR solutions firm is developing software for staffing agencies that uses machine learning.
The team uses training data to teach the algorithm and discovers that it generates lower employability scores for women. Also, it predicts that women, especially with children, are less likely to get a high-paying job.
Which type of bias has been discovered?
In general, models that perform their tasks:
What is the open framework designed to help detect, respond to, and remediate threats in ML systems?
A dataset can contain a range of values that depict a certain characteristic, such as grades on tests in a class during the semester. A specific student has so far received the following grades: 76,81, 78, 87, 75, and 72. There is one final test in the semester. What minimum grade would the student need to achieve on the last test to get an 80% average?
Which of the following is TRUE about SVM models?
Which of the following is a common negative side effect of not using regularization?
Which of the following is the correct definition of the quality criteria that describes completeness?
Which of the following algorithms is an example of unsupervised learning?
Why do data skews happen in the ML pipeline?
Copyright © 2021-2026 CertsTopics. All Rights Reserved
